
039 线程概念

039 线程概念
小米里的大麦线程概念
1. 什么是线程?它和进程的关系?
1. 粒度:执行的“颗粒大小”
粒度(Granularity) 是个比喻术语,表示一个单位在调度或执行上的“精细程度”。举例说明:
进程 是一个较大单位(粗粒度):拥有独立地址空间、资源。
线程 是进程内部的小单位(细粒度):共享地址空间,调度更轻便。
比喻一下:一个公司(进程)可能有多个部门(线程),每个部门是公司内部的执行单位,共享同一个资源(办公室、资金)。
线程执行进程的代码(粒度细)
- 多线程可以同时执行同一个进程的多个代码分支,这比进程切换效率高。
- 一个进程内部多个线程共同完成任务,就像车间里多个工人一起干活。
2. 线程的定义
线程是操作系统调度的最小执行单位。
在用户/开发者角度看:线程是进程中的“执行分支”,多个线程可以并发执行进程中的不同任务。
在内核角度看:内核调度的是线程(Linux 称为“轻量级进程”),不是传统意义上的进程。
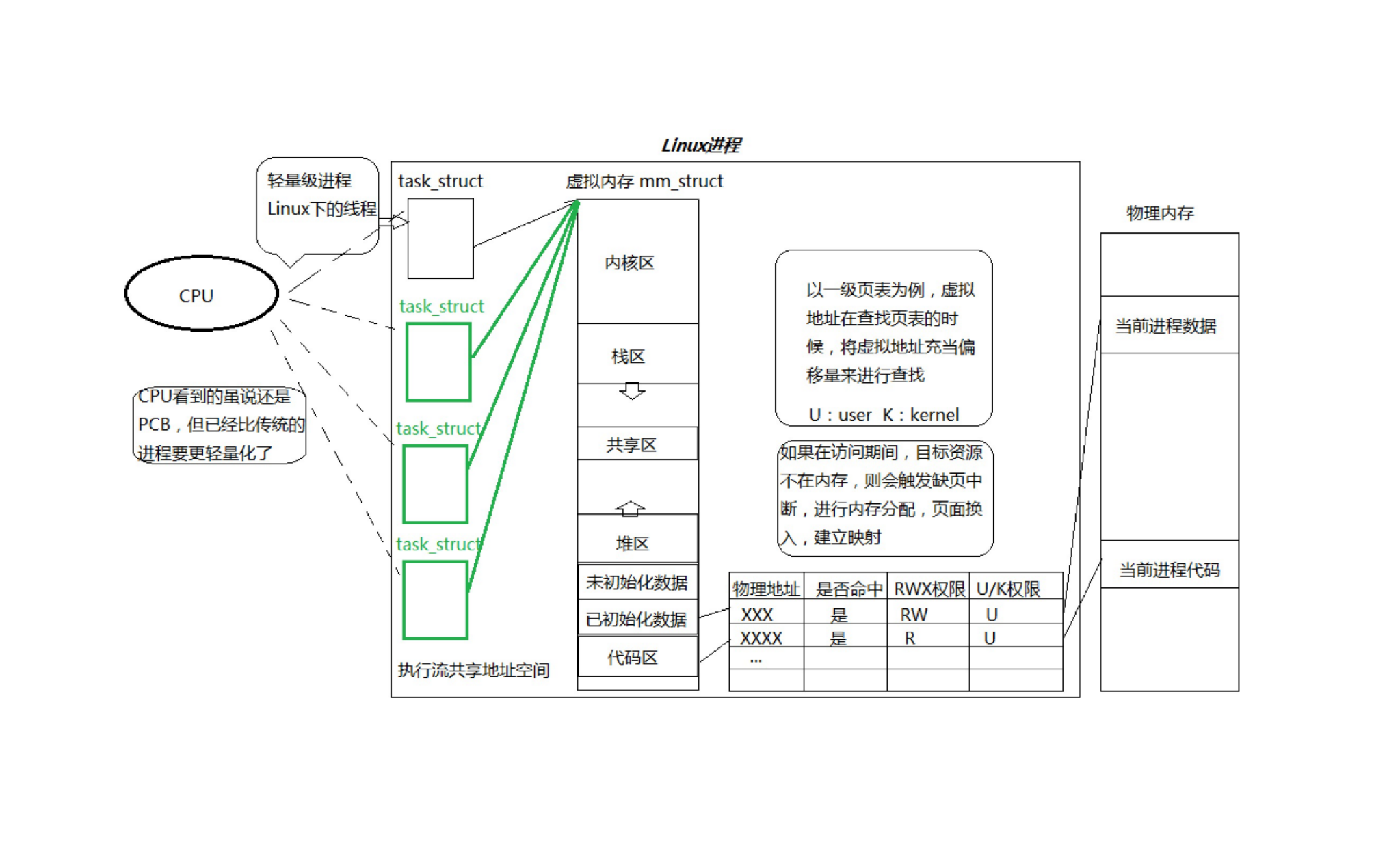
CPU 视角:只有“执行流”,每个 task_struct(无论是进程还是线程)在 CPU 看来都是“可调度实体”。因此 Linux 把线程干脆叫“轻量级进程”——名字里仍带“进程”,只是资源复用程度不同。
执行流 = CPU 上能被调度运行的最小单位,无论是:主线程执行
main()、子线程处理任务、内核线程处理 I/O、甚至信号处理函数上下文切换,本质上,它们都是“一个在 CPU 上执行的流动单元”。所以我们抽象地称它为 执行流。CPU 只调度执行流(线程):CPU 的调度单位是线程(执行流),不是进程。所以:CPU 只管“谁来执行”,而不是“哪个进程”执行。
3. Linux 中线程的实现方式?
PCB 结构理解(进程是资源实体):进程 = PCB(Process Control Block) + 代码/数据
- PCB 记录了进程的所有管理信息(PID、状态、内存映射、文件表等)。
- 线程依附进程执行,不拥有自己的完整 PCB,只在进程的 PCB 中挂靠自己的线程控制块。
Linux 并没有原生的“线程”这个独立结构,而是通过内核的 进程机制(task_struct) 来实现线程,无论是普通进程、还是线程,在内核中都是 task_struct 实例。在 Linux 中,线程就是一种特殊的“进程”,又叫 轻量级进程(Lightweight Process,LWP)。多个线程共享同一个进程的资源(代码段、数据段、堆、文件描述符等),但有自己独立的:
- 栈空间(私有栈)
- 寄存器现场(上下文)
- 线程 ID(TID)
[!NOTE]
那这样做的好处(优雅性)是什么?
这正是 Linux/OS 设计哲学的体现:
- 统一的数据结构,简化调度系统。
- 灵活的共享机制。
- 复用代码(内核的数据结构),降低 bug 的可能性和维护难度。
Windows 内核线程是“真正意义上的线程”:Windows 内核中有 线程控制块,叫做 TCB(
struct TCB,Thread Control Block)。它是 Windows 原生线程结构,用于记录线程上下文、栈地址、状态等,是 Windows 的调度单位。Windows 中,进程是资源容器,线程是独立的执行单位,系统明确区分这两个概念。
4. 为什么线程要在进程“内部”执行?
- 原因:线程不拥有自己的资源,必须依附进程的资源(如地址空间)才能执行。 任何执行流想跑起来都必须:有代码(指令)、有栈、有页表(地址空间)(加粗是必要条件!),全部条件还需要 task_struct(调度实体)、上下文。
- 所以:“地址空间是进程的资源窗口”,线程就是进程内部的执行分支。线程“在进程地址空间内跑”不是可选,而是必选项;离了地址空间,CPU 连下一条指令在哪都不知道。
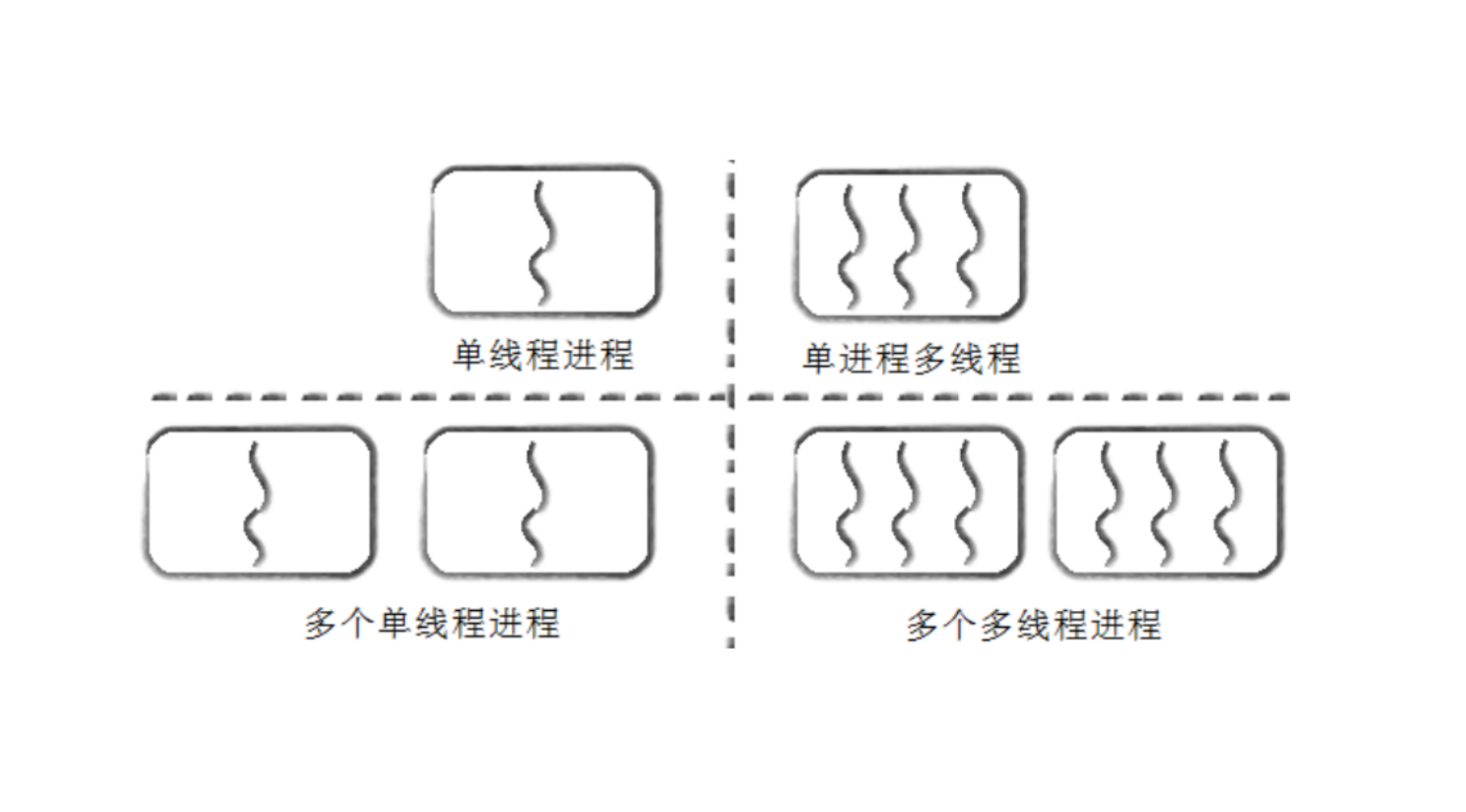
5. 进程 vs 线程
【os 浅尝】话说进程和线程~ | B 站
进程和线程的区别 | B 站
【操作系统】进程和线程的区别 | B 站
线程、进程和应用程序的关系和原理(干货教程) | B 站
| 对比点 | 进程 | 线程 |
|---|---|---|
| 是否独立 | 独立,拥有自己的地址空间、页表 | 依附于进程,共享进程地址空间 |
| 是否拥有资源 | 是,拥有文件描述符、内存等 | 否,只拥有少量运行所需资源 |
| 调度粒度 | 粗(整个进程调度) | 细(线程调度) |
| 创建/销毁开销 | 大(复制页表、资源) | 小(切换栈、寄存器) |
| 通信效率 | 低(需进程间通信 IPC) | 高(共享内存) |
| 健壮性 | 进程崩溃不影响其他进程 | 线程崩溃导致整个进程崩溃 |
2. 页表
「Coding Master」第 30 话 这个内存分页,就挺难的 | B 站
1. 什么是页表(Page Table)?
1. 本质
页表是操作系统用来 管理虚拟地址与物理地址映射关系 的数据结构。每个进程都有自己的 虚拟地址空间 ,而页表就是这个地址空间的“地图”,告诉 CPU 如何将一个虚拟地址转换为物理地址。简单说:我们访问的是虚拟地址,系统通过页表找出对应的物理地址。
2. 页表的核心单位
| 名称 | 含义 | 单位 | 特点 | 举例 |
|---|---|---|---|---|
| 页面(Page) | 虚拟地址空间被划分为固定大小的块 | 通常为 4KB | 虚拟地址的基本单位 | 每个页面对应一个物理页框 |
| 页框 / 页帧(Page Frame) | 物理内存被划分为固定大小的块 | 通常为 4KB | 存放页面数据的物理单元 | 物理内存中的 4KB 单元 |
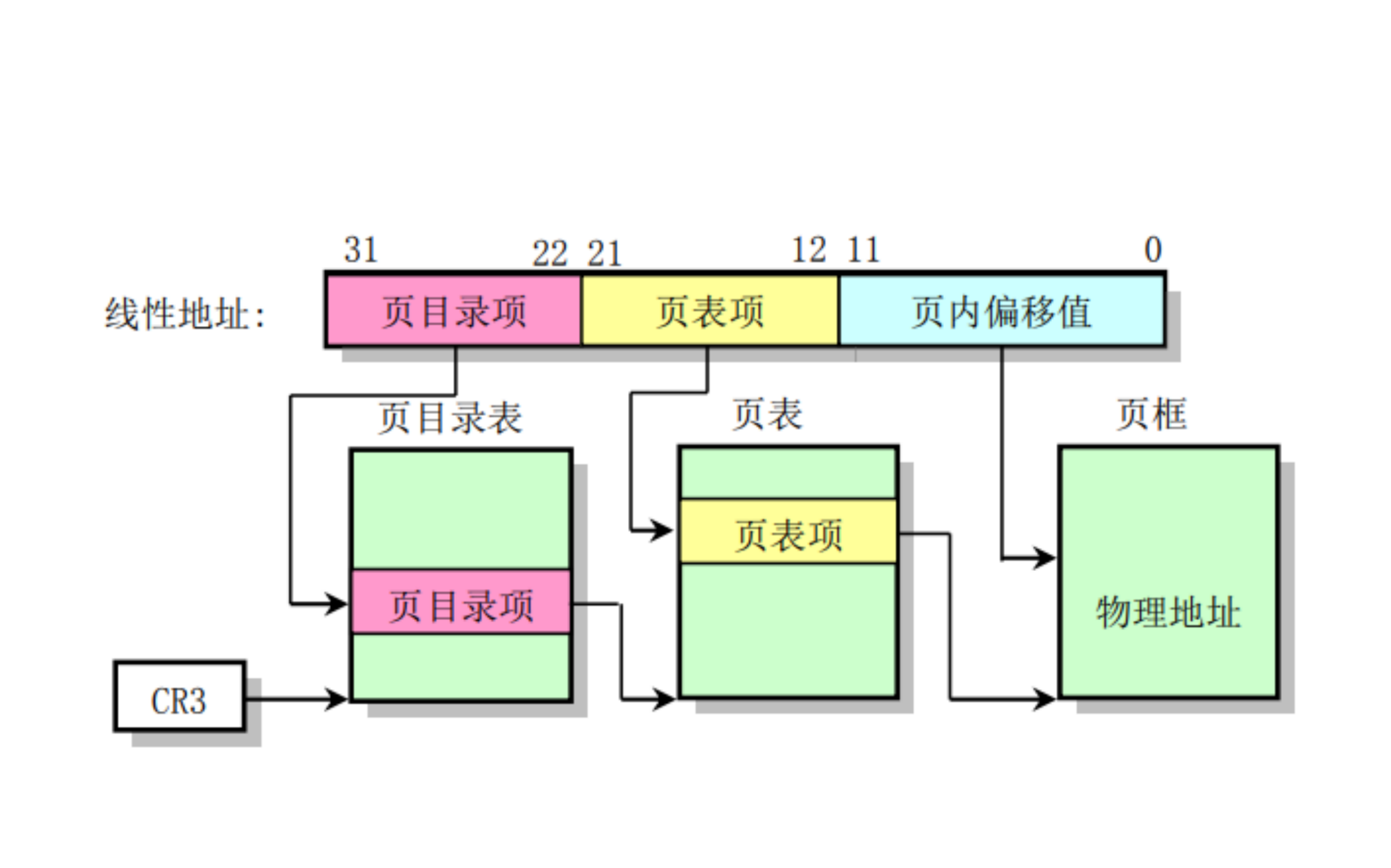
| 页目录项(PDE) | 一级页表项,指向页表 | 4 字节(32 位) | 页目录有 1024 项 | PDE [i] → 页表起始地址 |
| 页表项(PTE) | 二级页表项,指向页框 | 4 字节(32 位) | PTE [i] → 页框起始地址 | 用于虚拟地址到物理地址映射 |
| 页内偏移(Offset) | 页内地址偏移量 | 12 位(0~4095) | 用于在页框中定位具体字节 | 偏移量 + 页框地址 = 物理地址 |
3. 为什么需要页表?
页表是实现虚拟内存机制的基础,二级页表是为了节省内存并提高效率,多级页表则是为了支持更大的地址空间和更灵活的管理方式。
为什么需要二级页表?
单级页表的问题(以 32 位系统为例):32 位系统地址空间为 4GB(2^32),页大小为 4KB(2^12),总共需要 2^20 = 1,048,576 个页表项,每个页表项 4 字节,总大小为 4MB。所以:页表大小 = 2²⁰ × 4B = 4MB,每个进程都要维护一张 4MB 的页表(即使它只用了一点虚拟内存),这对于上了年代的机器来说是灾难性设计!
就是因为占内存大、浪费严重、不支持“按需分配”所以诞生了二级页表,二级页表是对“空间换时间”的优化倒转 —— 用时间(多查一次)换空间(只分配用到的),再到后来的多级页表:节省空间、支持按需映射、提升效率。
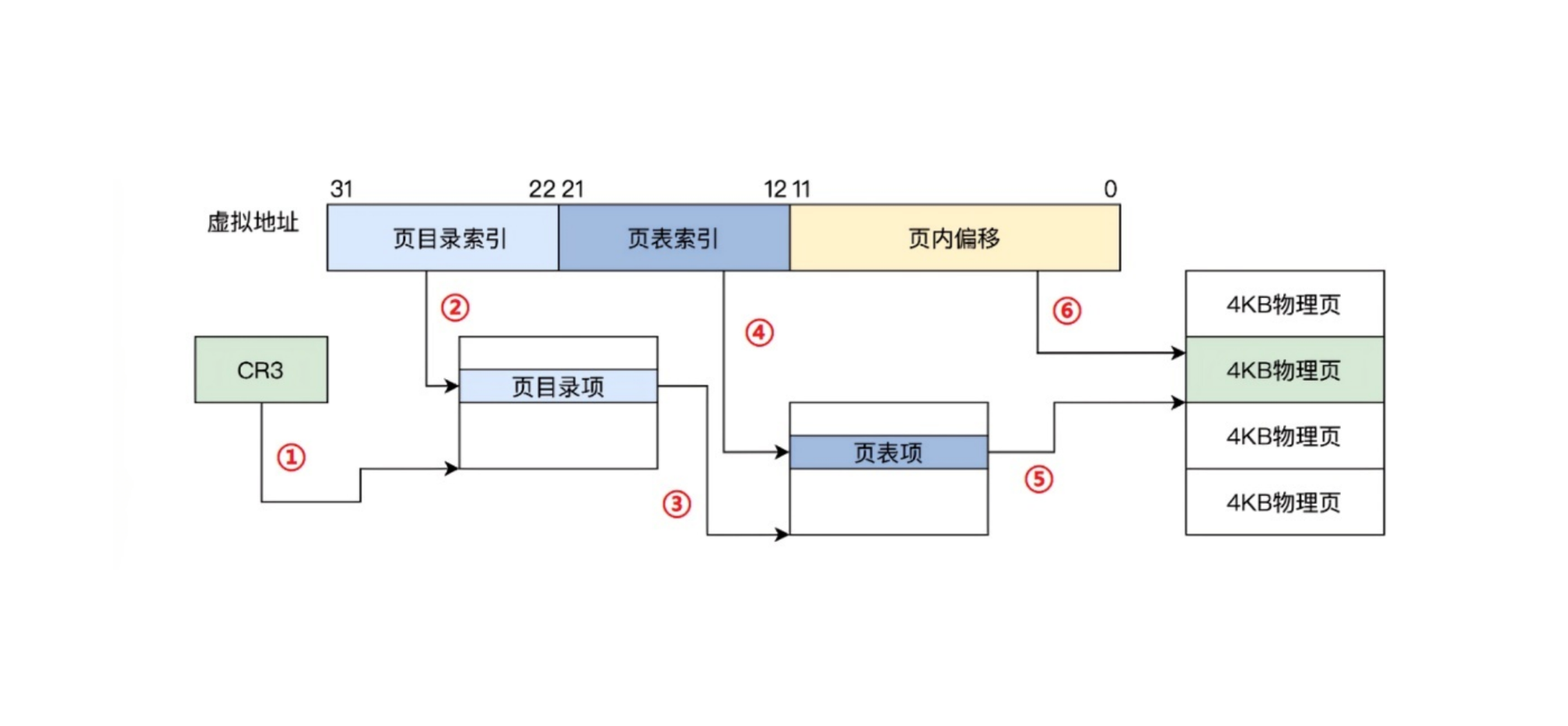
4. 32 位系统中二级页表的工作原理结构图
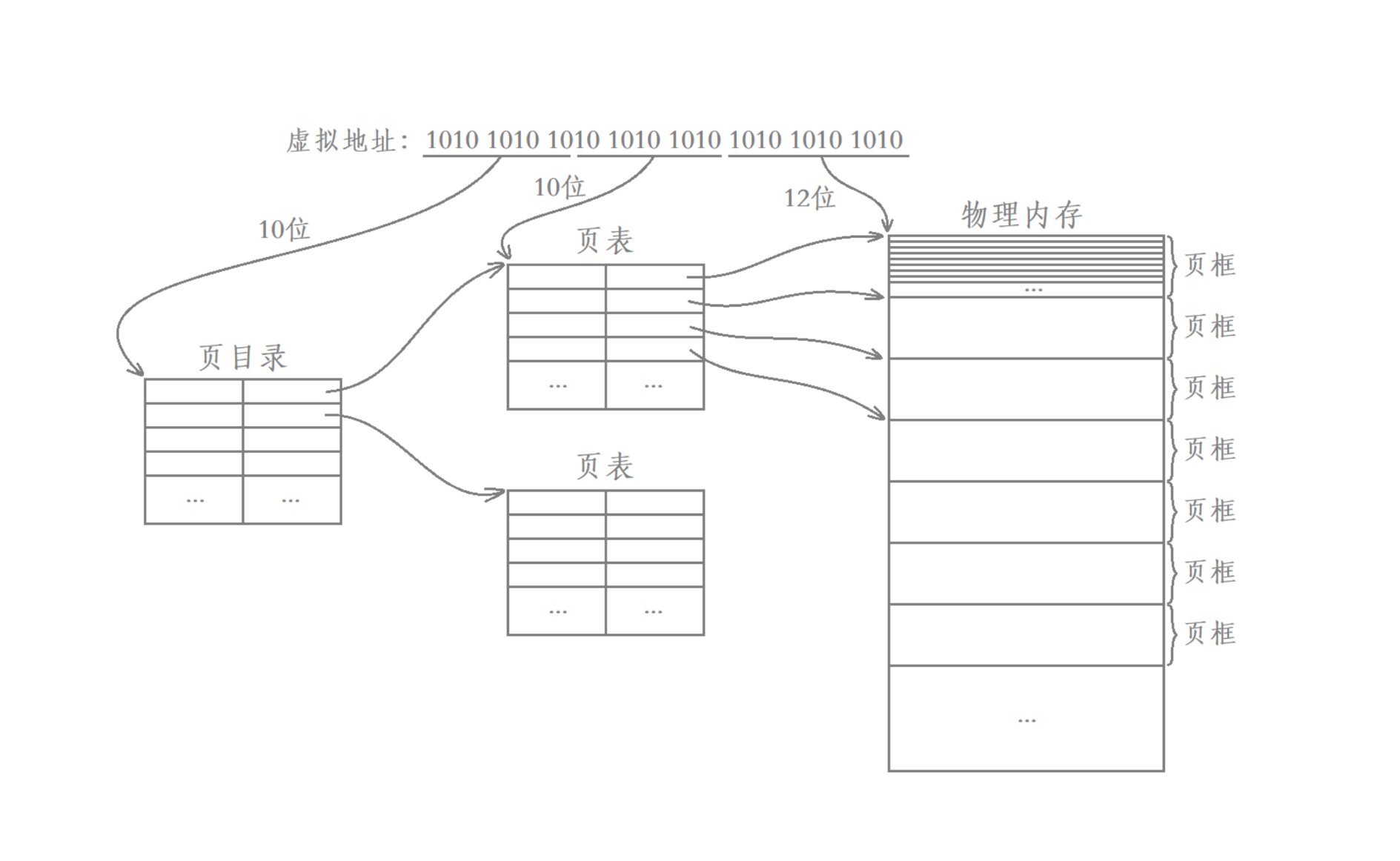
1. 分解说明
虚拟地址 = 32 位: 虚拟地址由 3 部分组成:
1
2[10位 页目录索引] [10位 页表索引] [12位 页内偏移]
(2^10 条) (2^10 条) (4KB 页面)页大小 = 4KB = 2¹²: 最后 12 位表示页内偏移(Offset)
页表项大小 = 4 字节(32bit): 一个页表(4KB)能容纳:4KB ÷ 4B = 1024 条项,刚好对应 2¹⁰。
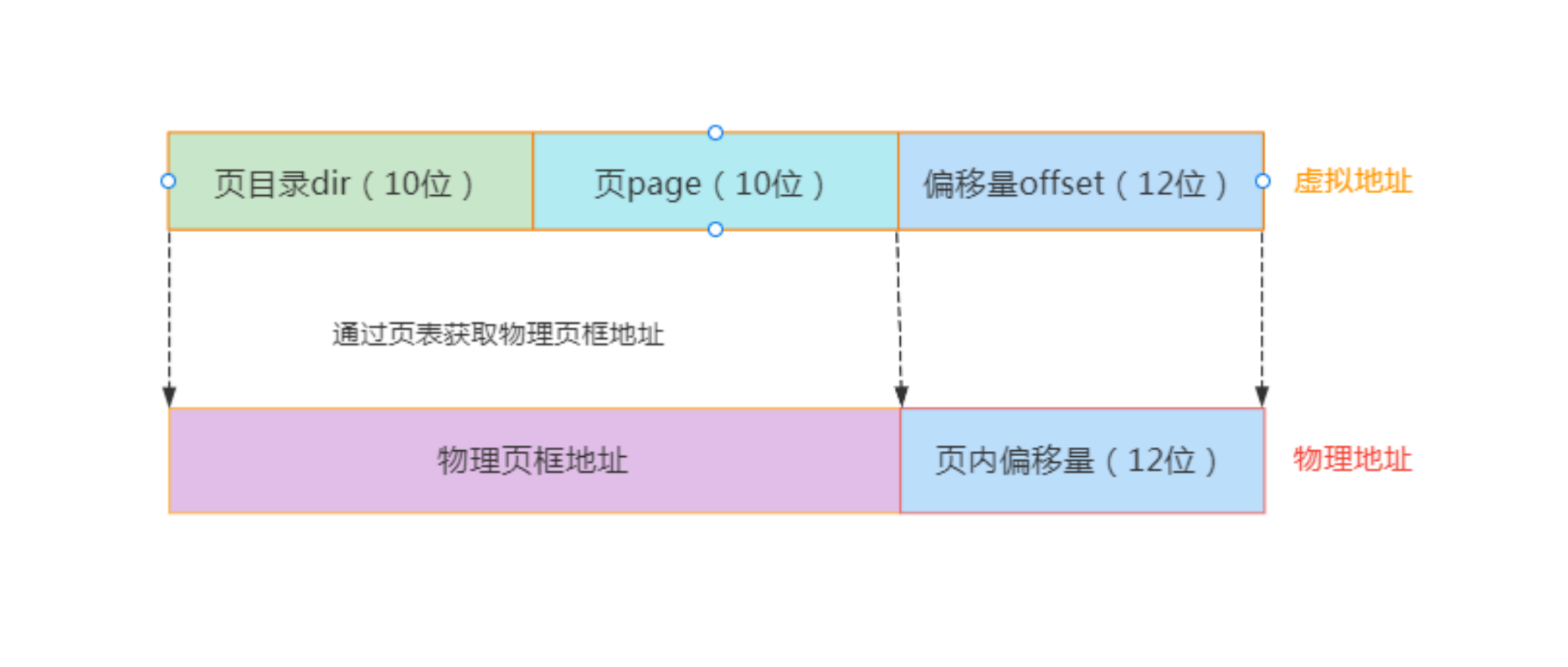
2. x86 32 = 10+10+12 的意义
虚拟地址 32 位 = 10(页目录)+ 10(页表)+ 12(偏移)
| 段 | 位数 | 说明 |
|---|---|---|
| 页目录 | 10 | 一级表,存放 页表的指针,选择哪个页表(共 1024 个) |
| 页表 | 10 | 二级表,存放 页 → 物理帧 映射,选择哪个页表项 |
| 偏移 | 12 | 不变,表示页中具体偏移地址(4KB 页大小) |
3. 再谈线程
1. 线程的优点(相对进程)
| 编号 | 优点描述 | 解释说明或场景举例 |
|---|---|---|
| 1 | 创建开销小 | 新线程共享父进程资源,不需要重新分配地址空间等 |
| 2 | 上下文切换代价小 | 线程切换只需切换少量寄存器,进程切换需切页表等 |
| 3 | 占用资源少 | 共享代码段、数据段、堆等,减少内存资源开销 |
| 4 | 支持并发执行 | 多线程可利用多核 CPU,提高执行效率 |
| 5 | 提升 IO 密集程序性能 | 下载、读写磁盘等可异步等待,主线程可继续执行 |
| 6 | 提升计算密集程序性能(多核) | 可将任务拆分成多个子任务,多个核并行执行 |
| 7 | IO 操作可并发等待,提高吞吐 | 多线程各自等待不同 IO 资源,实现重叠与效率提升 |
2. 线程的缺点
| 编号 | 缺点描述 | 举例或解释 |
|---|---|---|
| 1 | 同步/调度带来性能损失 | 多个计算密集型线程争抢 CPU,带来线程调度/同步开销 |
| 2 | 健壮性降低 | 不小心共享了不该共享的变量,或同步出错易出 bug |
| 3 | 缺乏访问隔离保护 | 所有线程共享进程资源,某线程异常可能影响整个进程 |
| 4 | 编程难度高 | 多线程程序调试困难,如死锁、竞态条件难定位 |
3. 线程异常处理风险(容易忽略)
| 问题 | 描述说明 |
|---|---|
| 崩溃传染性强 | 一个线程崩溃(如除 0、野指针),触发信号机制,整个进程被终止 |
| 同步问题 | 锁没加好、条件变量判断失误,可能引发死锁、数据污染等不可预测问题 |
| 资源泄漏 | 某线程提前崩溃未释放资源,整个进程泄漏,所有线程随之退出 |
4. 线程适用场景(牢记)
| 场景 | 类型 | 描述示例 |
|---|---|---|
| CPU 密集型 | 多核计算 | 视频渲染、图片处理、机器学习模型训练、加密解密 |
| IO 密集型 | 高并发 IO | 网络爬虫、数据库操作、磁盘文件下载、日志写入 |
| 用户体验优化 | 前后台并行处理 | 一边写代码一边下载依赖,一边加载图片一边展示 UI |
5. 记忆口诀
- 线程优点快轻小,共享资源效率高;
- 线程缺点易崩溃,调试困难需谨慎;
- CPU 并行靠分工,IO 并发靠等待;
- 善用线程提性能,滥用线程埋雷坑。
线程相较于进程最大的优势是开销小、切换快、共享资源,适合高并发或高性能场景。比如在多核处理器中跑 CPU 密集任务,或者处理大量 IO 等待时都能有效提升效率。但线程也存在缺乏隔离、同步复杂、异常传播等风险,因此使用时需要严格管理共享资源和同步机制。













