
025 理解文件系统

025 理解文件系统
小米里的大麦理解文件系统
1. 认识磁盘磁带
由于磁盘磁带和操作系统组成原理更相关,而且相关概念用语言太抽象,所以我找到了一些比较好的视频和书籍内容来帮助理解(注意视频、书籍内容有部分知识我们不涉及,所以不懂也没关系,多出的就当是眼界扩展了):
摘自《操作系统概念精要 原书第 2 版》
298页前后(真的是很想将内容直接摘过来,奈何实在是没找到电子版,只能扫描现书将就看吧 😂)。这里的图片已经排好序,直接按照顺序看即可。推荐直接去看原书,也希望有电子版的进行贡献一下,感谢您的开源精神!








自然也少不了鸟哥啦~ 摘自《鸟哥的 Linux 私房菜 基础学习篇(第四版)》
210~217页相关内容。还是推荐看原书,就不过多赘述了。首先说明一下磁盘的物理组成,整颗磁盘的组成主要有:
- 圆形的盘片(主要记录数据的部分);
- 机械手臂,与在机械手臂上的磁头(可读写盘片上的数据);
- 主轴马达,可以转动盘片,让机械手臂的磁头在盘片上读写数据。
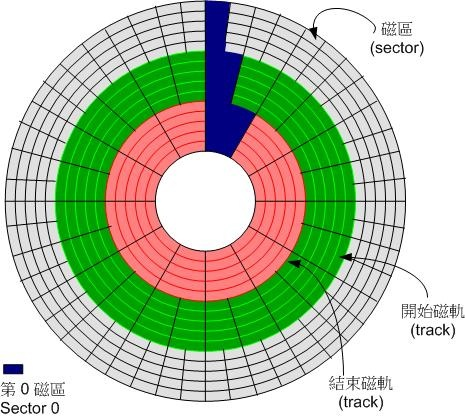
从上面我们知道数据储存与读取的重点在于盘片,而盘片上的物理组成则为(假设此磁盘为单碟片,盘片图示请参考第二章图 2.2.1 的示意):
- 扇区 (Sector)为最小的物理储存单位,且依据磁盘设计的不同,目前主要有 512Bytes 与 4K 两种格式;
- 将扇区组成一个圆,那就是柱面 (Cylinder) ;
- 早期的分区主要以柱面为最小分区单位,现在的分区通常使用扇区为最小分区单位(每个扇区都有其号码喔,就好像座位一样);
- 磁盘分区表主要有两种格式,一种是限制较多的 MBR 分区表,一种是较新且限制较少的
GPT分区表。MBR分区表中,第一个扇区最重要,里面有:主引导记录(Master boot record,MBR)及分区表 (partition table) , 其中MBR占有446B, 而分区表则占有64B。GPT分区表除了分区数量扩充较多之外,支持的磁盘容量也可以超过2TB。至于磁盘的文件名部份,基本上,所有物理磁盘的文件名都已经被仿真成
/dev/sd[a-p]的格式,第一块磁盘文件名为/dev/sda。而分区的文件名若以第一块磁盘为例,则为/dev/sda[1-128]。除了物理磁盘之外,虚拟机的磁盘通常为/dev/vd[a-p]的格式。复习完物理组成后,来复习一下磁盘分区吧!如前所述,以前磁盘分区最小单位经常是柱面,但 CentOS7 的分区软件,已经将最小单位改成扇区了,所以容量大小的分区可以切的更细 〜 此外,由于新的大容量磁盘大多得要使用
GPT分区表才能够使用全部的容量,因此过去那个MBR的传统磁盘分区表限制就不会存在了。不过,由于还是有小磁盘啊!因此,你在处理分区的时候,还是得要先查询一下,你的分区是MBR的分区?还是GPT的分区?在第三章的 CentOS7 安装中,鸟哥建议过强制使用GPT分区喔!文件系统特性
传统的磁盘与文件系统之应用中,一个分区就是只能够被格式化成为一个文件系统,所以我们可以说一个文件系统就是一个硬盘分区。但是由于新技术的利用,例如我们常听到的
LVM与软件磁盘阵列 (softwareraid),这些技术可以将一个分区格式化为多个文件系统(例如LVM),也能够将多个分区合成一个文件系统 (LVM,RAID)。所以说,目前我们在格式化时已经不再说成针对硬盘分区来格式化了,通常我们可以称呼 一个可被挂载的数据为一个文件系统而不是一个分区喔!那么文件系统是如何运行的呢?这与操作系统的文件数据有关。较新的操作系统的文件数据除了文件实际内容外,通常含有非常多的属性,例如
Linux操作系统的文件权限 (rwx)与文件属性(拥有者丶用户组丶时间参数等)。文件系统通常会将这两部份的数据分别存放在不同的区块,权限与属性放置到inode中,至于实际数据则放置到数据区块中。 另外,还有一个超级区块 (super 数据区块) 会记录整个文件系统的整体信息,包括inode与数据区块的总量、使用量、剩余量等。每个
inode与区块都有编号,至于这三个数据的意义可以简略说明如下:
- 超级区块 ∶ 记录此 f 文件系统的整体信息,包括
inode与数据区块的总量、使用量、剩余量,以及文件系统的格式与相关信息等;inode:记录文件的属性,一个文件占用一个inode,同时记录此文件的数据所在的区块号码;- 数据区块:实际记录文件的内容,若文件太大时,会占用多个区块。
由于每个
inode与数据区块都有编号,而每个文件都会占用一个inode,inode内则有文件数据放置的数据区块号码。因此,我们可以知道的是,如果能够找到文件的inode的话,那么自然就会知道这个文件所放置数据的数据区块号码,当然也就能够读出该文件的实际数据了。这是个比较有效率的作法,因为如此一来我们的磁盘就能够在短时间内读取出全部的数据,读写的性能比较好啰。我们将
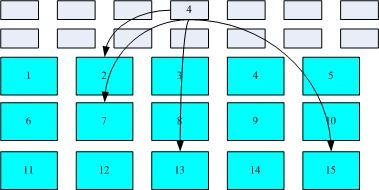
inode与数据区块区块用图解来说明一下,如下图所示,文件系统先格式化出inode与数据区块的区块,假设某一个文件的属性与权限数据是放置到inode 4号(下图较小方格内),而这个inode记录了文件数据的实际放置点为 2,7,13,15 这四个数据区块号码,此时我们的操作系统就能够据此来排列磁盘的读取顺序,可以一口气将四个数据区块内容读出来!那么数据的读取就如同下图中的箭头所指定的模样了。
这种数据存取的方法我们称为索引式文件系统 (indexed allocation)。那有没有其他的惯用文件系统可以比较一下啊?有的,那就是我们惯用的 U 盘(闪存),U 盘使用的文件系统一般为
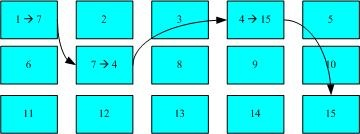
FAT格式。FAT这种格式的文件系统并没有inode存在,所以FAT没有办法将这个文件的所有区块在一开始就读取出来。每个区块号码都记录在前一个区块当中,他的读取方式有点像下面这样:
上图中我们假设文件的数据依序写入
1->7->4->15号这四个 block 号码中,但这个文件系统没有办法一口气就知道四个区块的号码,他得要一个一个的将区块读出后,才会知道下一个区块在何处。如果同一个文件数据写入的区块分散的太过厉害时,则我们的磁头将无法在磁盘转一圈就读到所有的数据,因此磁盘就会多转好几圈才能完整的读取到这个文件的内容!常常会听到所谓的碎片整理吧?需要碎片整理的原因就是文件写入的区块太过于离散了,此时文件读取的性能将会变的很差所致。 这个时候 可以通过碎片整理将同一个文件所属的区块集合在一起,这样数据的读取会比较容易啊! 因此,
FAT的文件系统需要时不时的碎片整理一下,那么Ext2是否需要磁盘重整呢?由于
Ext2是索引式文件系统,基本上不太需要常常进行碎片整理的。但是如果文件系统使用太久,常常删除、编辑、新增文件时,那么还是可能会造成文件数据太过于离散的问题,此时或许会需要进行重整一下的。不过,老实说,鸟哥倒是没有在Linux操作系统上面进行过Ext2/Ext3文件系统的碎片整理,似乎不太需要啦!太多了,还是看图片吧 😂


2. 磁带、HDD、SSD 数据存储原理与演进
磁带是最古老的电子数据存储技术之一,其介质为带有磁性涂层的长条塑料薄膜。数据以磁化痕迹形式记录在磁带上:写入时磁头通过控制磁场使带面上的磁性颗粒朝向发生改变,分别表示二进制的 0 或 1;读取时固定的磁头感应这些磁化痕迹输出数据。磁带基片通常是聚酯薄膜,上面涂覆氧化铁或金属磁粉层。磁带读取为串行访问,速度较慢但容量极大,而且成本低廉、耐用性高,因此常用于海量数据的长期归档和备份。
小知识
- 固态硬盘(SSD):不属于磁盘或硬盘(HDD),因其使用闪存芯片而非磁性介质。
- 关系总结:
- 磁盘 是技术大类(磁性存储),硬盘 是磁盘的现代主流应用。
- 日常中“磁盘”有时被误用作“硬盘”的同义词,但严格意义上前者更广泛。
| 对比项 | 硬盘(HDD, Hard Disk Drive) | 磁盘(广义) | 关系说明 |
|---|---|---|---|
| 定义 | 一种使用磁性存储技术的物理存储设备,属于磁盘的一种具体类型。 | 广义指所有利用磁性记录数据的圆形盘片(如软盘、硬盘中的盘片)。 | 硬盘是磁盘的一种具体应用形式,磁盘的概念更广泛。 |
| 存储原理 | 通过磁头在高速旋转的磁性盘片上读写数据。 | 依赖磁性材料记录数据(如硬盘盘片、软盘等)。 | 硬盘的存储基于磁盘的磁性原理。 |
| 常见类型 | 机械硬盘(HDD) | 包括硬盘中的盘片、软盘(Floppy Disk)、早期磁光盘(MO)等。 | 硬盘是磁盘技术的主流应用之一,其他磁盘类型逐渐被淘汰或小众化。 |
| 速度 | 较慢(依赖机械转动,通常转速 5400/7200 RPM)。 | 取决于类型(如软盘速度远低于硬盘)。 | 硬盘速度优于大多数传统磁盘介质。 |
| 容量 | 大(当前主流 1TB~20TB)。 | 差异大(软盘仅 1.44MB,硬盘盘片单碟可达数 TB)。 | 硬盘是磁盘技术中容量发展的巅峰代表。 |
| 体积/便携性 | 体积较大(3.5 英寸或 2.5 英寸)。 | 灵活(软盘小巧,硬盘盘片不可单独使用)。 | 磁盘的形态多样,硬盘更注重固定存储。 |
| 应用场景 | 电脑、服务器等大容量存储需求。 | 历史曾用于数据交换(软盘)、临时存储等,现硬盘主要用于长期存储。 | 硬盘取代了多数传统磁盘的用途。 |
| 价格 | 较低(单位容量成本低)。 | 历史中软盘成本低,但现代高性能磁盘(如企业级硬盘)价格较高。 | 硬盘性价比高,是磁盘技术的经济化产物。 |
| 发展趋势 | 逐渐被 SSD 替代,但仍在大容量存储中占优。 | 传统磁盘技术(如软盘)已淘汰,硬盘技术仍在优化。 | SSD(固态硬盘)不属于磁盘范畴,但硬盘仍是磁性存储的重要选择。 |
3. 硬盘 (HDD) 存储原理
硬盘通过磁性方式在旋转的盘片上存储二进制数据。 每个盘片表面涂覆磁性材料,盘片由主马达高速旋转,而机械臂上的磁头在盘片上方移动进行读写。盘片表面被划分为同心圆形的磁道(track)和扇区(sector),每个扇区通常固定容量(如 512B 或 4096B);这些磁道和扇区号构成了数据的物理地址。盘片上的微小磁颗粒可以被磁化成两种极性,分别代表二进制 0 和 1。写入时,磁头在线圈通电后在盘片下方产生磁场,将被选区域的小颗粒磁极方向改变以记录信息;读取时,磁头感知磁性材料的极性排列并将其转换为电信号恢复出数据。HDD 提供随机访问能力,因而读写延迟主要受磁头寻道和盘片旋转时间影响。

4. 固态硬盘 (SSD) 存储原理
SSD 使用闪存芯片(典型的 NAND Flash)作为存储介质,无机械活动部件。每个闪存单元是一个带浮栅的 MOSFET 晶体管,通过存储电荷来保存数据。当浮栅中注入电子时,晶体管阈值变化被解读为二进制“0”;当浮栅不带电子时则被视为二进制“1”。SSD 写入数据时,控制器通常需要先擦除整个块(块内所有单元恢复为空状态),然后才将新数据写入(利用高压使电子通过隧道注入浮栅)。由于没有机械部件,SSD 读写速度远快于 HDD。另一方面,闪存擦写次数有限,SSD 控制器必须使用磨损平衡(wear leveling)和 TRIM 等技术均衡使用单元并回收空间。总的来说,SSD 速度高、无噪音、功耗低,但成本相对较高且写入寿命有限。

5. HDD 未被淘汰的原因
虽然 SSD 性能优秀,但 HDD 凭借成本和容量优势仍不可替代。根据权威资料,对于大容量、冷备份或归档场景,经济实惠的 HDD 依然是首选。AWS 指出“若需要高速频繁访问用 SSD;处理备份、归档或大容量存储时,普通硬盘是更好的选择”。此外,HDD 技术发展成熟,数据恢复难度更低,长期保存历史数据也更稳定可靠。有些公司可能会将用户长期不访问的数据/很多年前的数据从 SSD 迁移至磁盘,从而长期保存数据并节约成本。
上面我们已经基本上了解了磁盘磁带的构造和存储、读写的原理,下面就到我的讲解了:
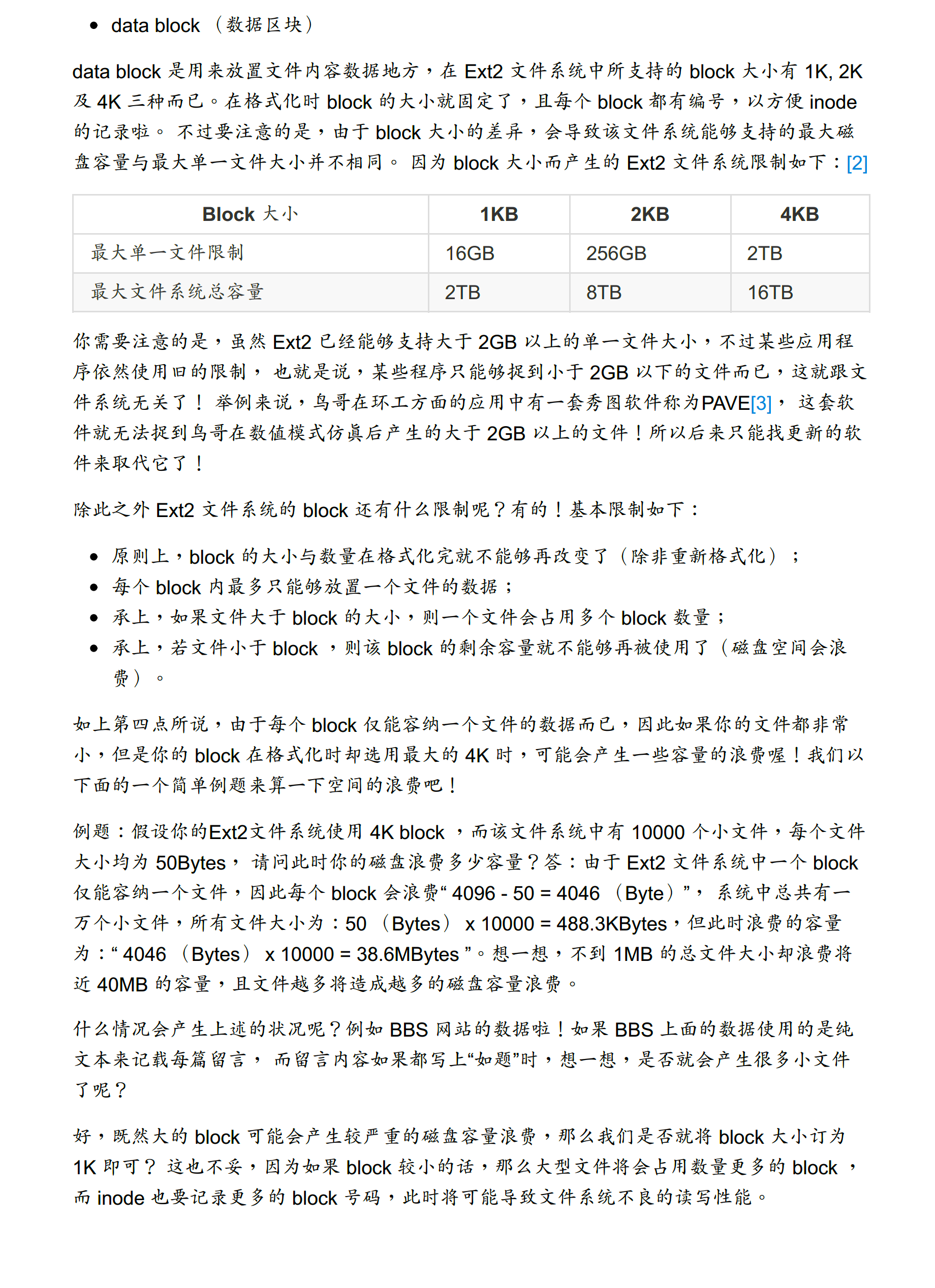
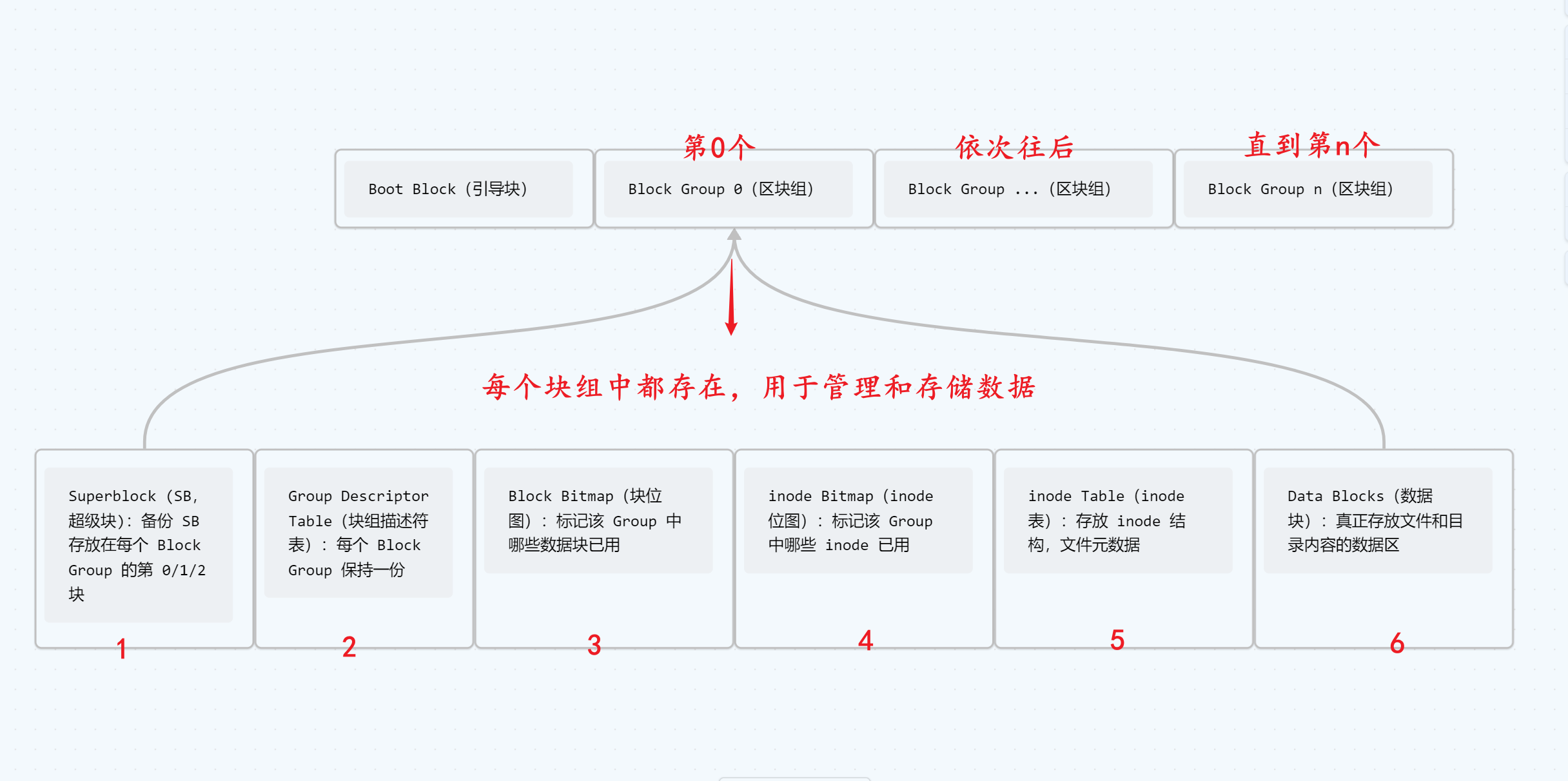
6. 文件系统磁盘布局(重点)
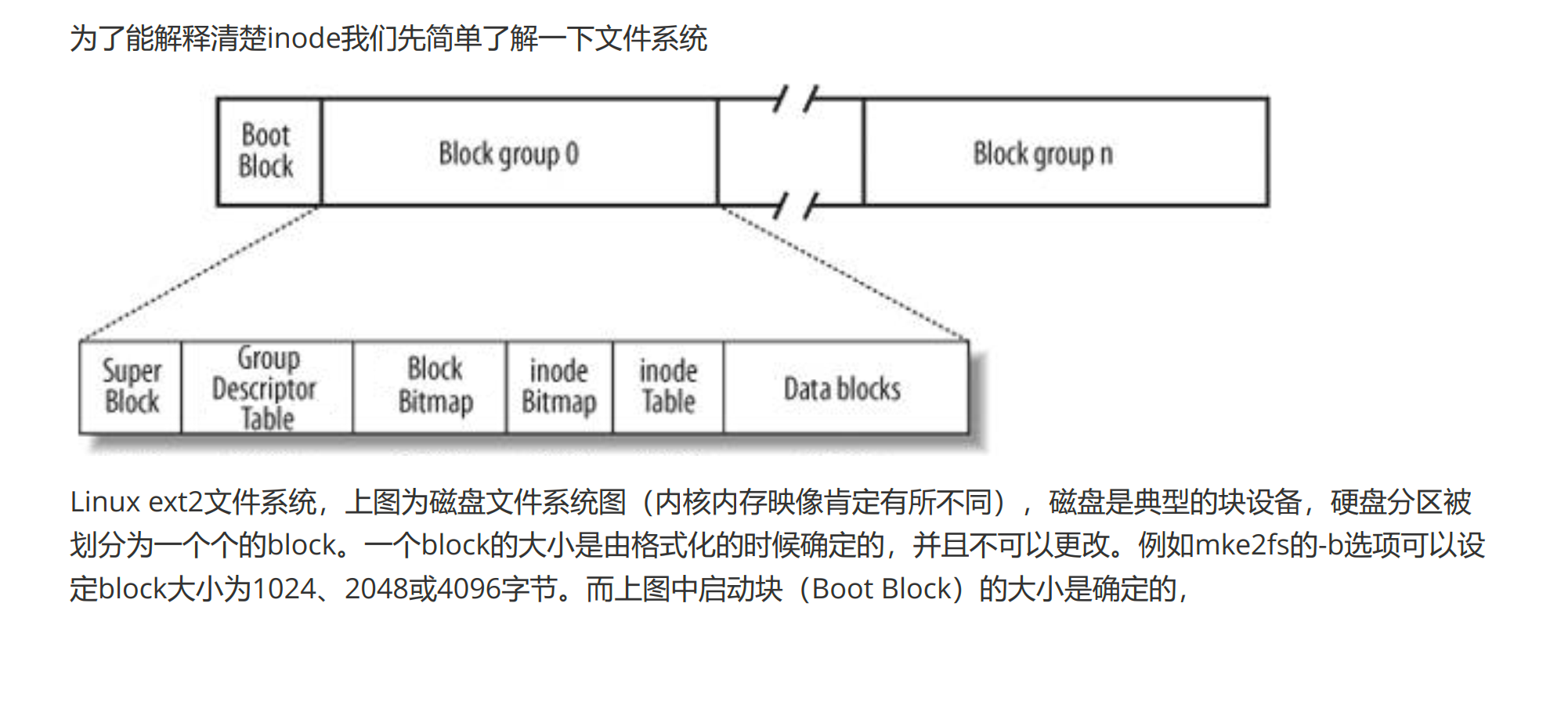
1 | +----------------------+ <- 偏移 0 |
注意:
Boot Block:文件系统第0块(通常1KB或2KB),包含启动加载代码,不属于文件系统使用范围,仅在可启动分区时有意义。Block Group:整个分区被划分成若干个相同大小的Block Group,以提高并行性并减少碎片。每个Group包含上述结构一次。
1. Boot Block(启动块/引导块)
- 大小:
1个块(BLOCK_SIZE),通常512B或4KB。 - 作用:存放引导代码(
Bootloader)及分区信息,在BIOS/UEFI加载文件系统之前被使用,文件系统本身不访问此区域。 - 存放位置:分区的第
0块。
2. Superblock (SB,超级块)
- 作用:文件系统的“总控信息”,记录整个分区的全局属性。
- 存放位置:分区的第
1块(紧跟Boot Block之后)。 - 大小:固定
1024 B。 - 关键字段:
- Magic Number(魔数):文件系统类型标识(如
0xEF53表示 Ext2/3/4)。 - Block Size(块大小):数据块大小(常见
4KB)。 - Total Blocks(总块数):总数据块数。
- Total Inodes(总
inode数):总inode数。 - First Inode(第一个
inode):第一个可分配inode(通常inode 2为根目录)。
- Magic Number(魔数):文件系统类型标识(如
- 冗余存储:备份
Superblock分布在各Block Group的第0/1/2块,防止损坏。
3. Group Descriptor Table (GDT,块组描述符表)
- 作用:描述每个
Block Group的布局信息(如位图、inode表的位置)。 - 存放位置:紧跟主
Superblock之后,占用若干个块。 - 描述符大小:32 B/个。
GroupDescriptorTable的总大小 = 描述符数 × 32,向上对齐到BLOCK_SIZE。 - 关键字段:
block_bitmap(块号): 指向当前Group的Block Bitmap的块号。inode_bitmap(块号): 指向当前Group的inode Bitmap的块号。inode_table(起始块号): 指向当前Group的inode Table的起始块号。- 空闲块数、空闲
inode数等统计信息。
4. Block Bitmap(块位图)
- 作用:位图方式标记本组中各数据块是否已分配。
- 存放位置:由
GDT中的block_bitmap字段指定。 - 大小:1 个
BLOCK_SIZE(例如 4KB = 32768 bits,能管理 32768 个块 ≈128MB)。 - 标记规则:1 = 已分配,0 = 空闲。
5. Inode Bitmap(inode 位图)
- 作用:位图方式标记本组中各
inode是否已分配。 - 存放位置:由
GDT中的inode_bitmap字段指定。 - 大小:1 个
BLOCK_SIZE(例如4KB可管理32768个inode)。 - 标记规则:1 = 已分配,0 = 空闲。
6. Inode Table(inode 表)
- 作用:存储所有文件/目录的元信息,每个
inode大小通常为128B或256B。 - 存放位置:由
GDT中的inode_table字段指定,长度 =(inodes_per_group * inode_size) / BLOCK_SIZE块。 - 关键字段:
- File Type:普通文件、目录、符号链接等。
- Permissions:访问权限(rwx)。
- File Size:文件大小。
- Timestamps:创建/修改/访问 时间戳。
- Data Block Pointers:直接指针(12 个)、一级/二级/三级间接指针。
7. Data Blocks(数据块)
- 作用:实际存放用户数据。所以,Linux 的文件在磁盘中存储是将属性和内容分开存储的!(文件内容 → 数据块,文件属性 →
inode)- 目录(directory):保存
<inode号, 文件名>的列表。 - 普通文件(file):存放文件内容的二进制数据。
- 目录(directory):保存
- 存放位置:紧跟在各组的
Inode Table之后,直至本组末尾。
| Block Group 字段 | 作用 | 大小/位置 |
|---|---|---|
| SuperBlock | 记录文件系统的全局信息(如总块数、inode 数、块大小等)。 | 每个 Group 可能有一份副本(冗余)。 |
| Group Descriptor Table | 描述当前 Block Group 的元数据(如块位图、inode 位图的位置)。 | 紧接 SuperBlock 之后。 |
| Block Bitmap | 标记当前 Group 中哪些数据块已被占用(1 = 占用,0 = 空闲)。 | 占用 1 个块,按位映射。 |
| inode Bitmap | 标记当前 Group 中哪些 inode 已被占用(类似 Block Bitmap)。 | 占用 1 个块,按位映射。 |
| inode Table | 存储 inode 数组,每个 inode 描述一个文件/目录的元数据(权限、大小、数据块指针等)。 | 占用多个块,具体取决于 inode 数量。 |
| Data Blocks | 实际存储文件数据的块。 | 剩余所有块。 |
8. 对比记忆
| 记忆 | 作用 | 类比 |
|---|---|---|
| SuperBlock | 文件系统的“总说明书”。 | 书的目录页。 |
| Group Descriptor Table | 描述每个 Block Group 的布局。 | 章节的页码索引。 |
| Block Bitmap | 标记哪些块被占用。 | 仓库货架占用表。 |
| inode Table | 存储文件元信息(如权限、大小)。 | 文件的属性卡。 |
| Data Blocks | 实际存储文件内容。 | 仓库里的货物。 |
7. 深入理解(重点)
1. 创建空文件的过程
- 查找空闲 inode:遍历
inode位图,找到一个空闲inode。 - 初始化 inode:在
inode表中找到对应inode,填入文件的属性信息(如创建时间、权限、大小等)。 - 关联目录项:在当前目录文件的数据块中,增加一条目录项(文件名 +
inode号)。
2. 写入文件的过程
- 根据文件名找到对应
inode(通过目录的数据块中查找inode号)。 - 读取
inode内容,查看已分配的数据块。 - 如果存在空余数据块,直接写入。
- 若数据块已满:
- 遍历块位图找到空闲数据块,分配并标记为已用。
- 在
inode中的数据块指针数组中记录该数据块号。 - 写入数据。
inode 与数据块的映射关系:
使用一个 15 元素的数组维护:
- 前
12个元素:直接指向12个数据块 - 后
3个元素:一级索引、二级索引和三级索引(用于数据块扩展)
3. 删除文件的过程
- 标记
inode无效:在inode位图中将对应inode置为无效。 - 标记数据块无效:在块位图中将文件使用的数据块置为无效。
- 删除映射关系: 删除对应目录文件中该文件的目录项(文件名和
inode号的映射关系)。
注意:删除操作只是标记为无效(标记为“可复用”)而非真正擦除数据,因此短时间内可恢复。后续文件操作可能重新分配这些
inode和数据块,导致原数据被覆盖。这也就是数据恢复的原理:删除 = 允许被覆盖。
为什么是“短时间”?
- 被标记为空闲的
inode号和数据块号可能在新文件或写入时重新分配。 - 一旦覆盖,原始数据就不可恢复。
4. 拷贝 vs 删除 的时间差异
- 拷贝文件慢:
- 创建新
inode。 - 分配多个数据块。
- 写入文件内容(复制)。
- 创建新
- 删除文件快:
- 只需修改
inode和块位图。 - 不需要物理/真实的删除文件内容。
- 只需修改
类比:
- 创建文件 = 建楼 → 慢
- 删除文件 = 在楼上写“拆”字 → 快
5. 目录的理解
- 在 Linux 中“一切皆文件”,目录也属于文件。
- 目录有自己的
inode(属性信息)和数据块(内容)。 - 目录的数据块内容:该目录下的文件名 与 对应
inode号的映射表。
目录权限:
- 无
w权限:无法创建文件。 - 无
r权限:无法查看文件列表。 - 无
x权限:无法进入目录。
特别说明:
- 文件名不存储在
inode中,而是存储在它所在目录文件的数据块中。 - 系统通过“目录项”建立文件名和
inode号的联系。
6. 文件系统中增删查改系统要做什么?
| 操作 | 系统执行的步骤概要 |
|---|---|
| 新建文件 | 分配 inode、数据块,更新目录项 |
| 删除文件 | inode/块标记无效,删除目录项 |
| 查找文件 | 遍历目录数据块,找 inode,再查 inode 内容 |
| 修改文件 | 定位 inode,追加/覆盖数据块 |
7. 查看文件的 inode 编号
1 | ls -i 文件名 |
- 使用者通过文件名访问文件。
- 内核通过目录项映射找到 inode。













