
02 数据库基础

02 数据库基础
小米里的大麦数据库基础
1. 什么是数据库?
数据库这个词,其实可以拆开来看:数据 + 库。库的意思就是“存放的地方”,数据库就是一个专门用来 高效存储、管理和操作数据 的系统。很多初学者会问:既然文件也能存数据,为什么还要数据库?答案就在于“管理和使用的便利性”。
- mysql 是数据库服务的客户端。
- mysqld 是数据库服务的服务器端。
- mysql 本质:基于 C(mysql)S(mysqld)模式的一种网络服务。
数据库本质:对数据内容存储的一套解决方案,我们给出字段或者要求,数据库直接给我们结果就行。
1. 用文件存数据的局限
虽然文件也能存储数据(比如.txt、.csv、.cpp),但面对现代应用的需求,文件方式存在明显缺陷:
- 安全性差: 无完善的用户权限控制,数据容易被篡改或泄露。
- 查询效率低: 每次查找都要遍历整个文件,数据量大时极慢。数据库则能用索引和优化算法做到毫秒级的查询。
- 管理困难: 缺乏统一结构,难以维护数据一致性、完整性。文件本质是“死”的存储,而数据库提供“关系模型”,能管理表与表之间的联系。比如订单和用户数据能通过
user_id关联。 - 不支持并发: 多人同时读写容易冲突、数据错乱。
- 扩展性差: 海量数据(比如 TB 级别)下文件系统难以支撑,IO 瓶颈严重。而数据库天生为大规模数据和高并发而优化。
- 程序使用不方便: 开发者需手动处理锁、缓存、索引、事务等复杂逻辑。而数据库有标准的 SQL(结构化查询语言),用统一的接口即可完成增删改查。
数据库正是为解决这些问题而生的:它提供 结构化存储、高效索引、事务支持、并发控制、权限管理、备份恢复等一整套成熟机制。所以,文件像是一个普通储物柜,而数据库更像是一个带标签、带检索系统、能自动归类、还能自动防盗和备份的智能档案馆。
2. 如何理解数据库?
- 物理层面: 数据最终还是存在磁盘或内存中,但数据库通过自己的引擎优化读写。比如把热点数据(经常访问的)放到内存里,以加快访问速度。
- 逻辑层面: 提供表、行、列、索引、视图等抽象,让开发者以“结构化方式”操作数据。
- 系统层面: 是一个独立运行的服务(如 MySQL Server),提供标准接口(如 SQL)供程序调用。
- 价值层面: 是现代信息系统的核心基础设施,是业务数据的“中枢神经”。
数据库水平是衡量程序员能力的一个重要指标 —— 因为几乎所有应用都离不开数据,而高效、稳定、安全地管理数据是硬功夫。
2. 主流数据库
市面上数据库大体可以分为 关系型数据库(RDBMS) 和 非关系型数据库(NoSQL),先看几个常见的:
| 数据库 | 特点 |
|---|---|
| SQL Server | 微软出品,与 Windows/.NET 生态深度集成,适合中大型企业项目,图形化管理工具强大,商业授权。 |
| Oracle | 企业级王者,功能强大、全面、稳定、适合 超大型复杂系统(如银行、电信),缺点:昂贵、并发处理上不如 MySQL,却在业务逻辑复杂时很强大。 |
| MySQL | 世界上使用最广、最流行的 开源 关系数据库,轻量、并发好、社区活跃,广泛用于 Web 应用(电商、SNS、论坛等)。 |
| PostgreSQL | 学术界起家,功能强大、标准兼容性好、支持 复杂查询和扩展,开源免费,学术和商业皆宜,被誉为“最接近 Oracle 的开源数据库”和“最先进的开源数据库” |
| SQLite | 嵌入式数据库,零配置、单文件、极轻量,不依赖服务器,适合移动端、桌面程序、嵌入式设备。 |
| H2 | Java 开发的嵌入式数据库,纯内存或文件存储,常用于单元 测试、原型开发、小型 Java 项目。 |
- 关系型数据库: 用“表格”的方式存数据,数据之间通过关系(外键、约束)来管理,核心是 SQL。
- 非关系型数据库: 不用固定表结构,数据可以是键值、文档、图或列存储,更灵活,适合海量和高并发场景。
MariaDB 是什么?
MariaDB 是 MySQL 被 Oracle 收购后,由 MySQL 原创始人 Michael Widenius 带领团队开发的分支(Fork),初衷是避免开源社区被垄断,保持 MySQL 的开源精神。它与 MySQL 高度兼容,多数场景下可无缝替换,换掉 MySQL 就能直接跑,且在并发性能、存储引擎和新功能上优化更优,发展更活跃。如今,CentOS 等主流 Linux 发行版已将 MariaDB 作为默认数据库,取代了原有的 MySQL。
MariaDB 的特点:
- 完全开源免费,社区驱动,发展活跃。与 MySQL 高度兼容,基本可以“无缝替换”。
- 性能优化更好,尤其在并发和存储引擎方面。新功能更快落地(如窗口函数、JSON 支持、GIS 增强等)。
简单说:MariaDB = MySQL 的开源精神继承者 + 性能增强版 + 社区友好版
3. 基本使用
1. 连接 MySQL 服务器
MySQL 本质上是一个 服务器进程,它监听某个端口(默认 3306),我们要通过客户端工具(mysql 命令、Navicat、程序代码)去连接。登录命令行:
1 | mysql -h 127.0.0.1 -P 3306 -u root -p |
参数解释:
-h:指明服务器地址(host),本地用127.0.0.1或localhost。-P:指明要访问的端口(Port)号,默认是3306,所以通常可以省略。-u:指明登录用户(名)(User),默认管理员账号是root。-p:指明要输入密码,不直接写密码在命令里(更安全)。
简化版:在本机上,端口没改,账号就是 root,那么我们可以直接使用
1 | mysql -u root -p # 本机最常用 |
输入密码(密码不回显)就能进去了。
2. 服务器、数据库、表关系
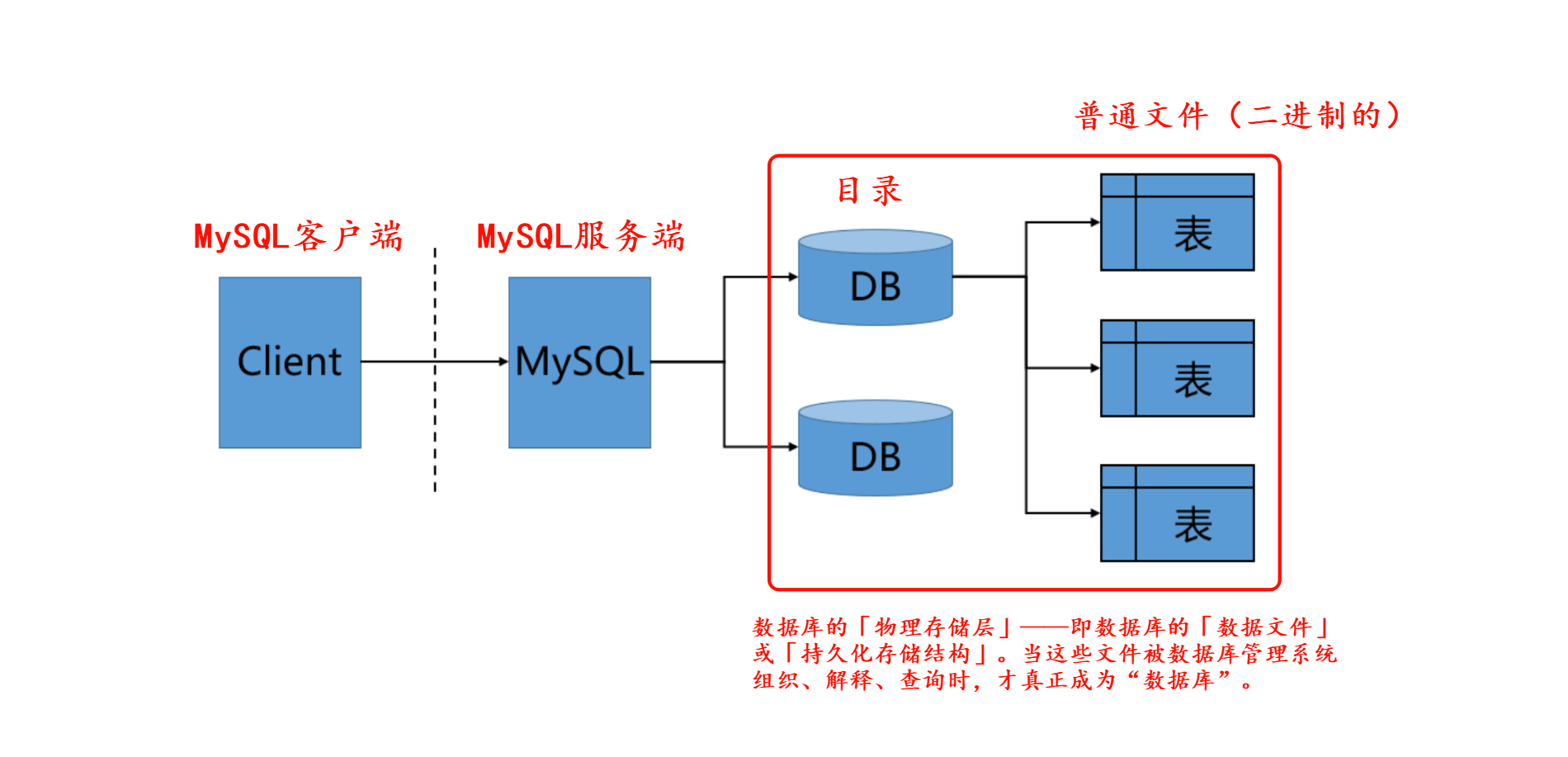
- 建立数据库,本质就是 Linux 下的一个目录。 在 MySQL 的默认配置下,数据库就是
/var/lib/mysql/下面的一个子目录。 在操作数据库时可另起窗口进行观察。 - 在数据库内建立表,本质就是在 Linux 下创建对应的文件即可!(表 = 目录里的文件)
- 数据库本质其实也是文件!!由 存储引擎 管理。只不过这些文件并不由程序员直接操作,而是由数据库服务帮我们进行操作。
1 | 服务器 (MySQL Server) |
可以这样理解:
- MySQL 服务器:像一个大仓库,负责管理一切数据。
- 数据库(Database):仓库里的一个“库房”,用来放一类相关数据。
- 数据表(Table):库房里的“柜子”,存放具体的数据。
- 记录(Row):柜子里的一条数据,相当于一张表格中的一行。
- 字段(Column):柜子里每个抽屉,相当于一张表格的一列。
也就是说:服务器 > 数据库 > 表 > 行/列。
3. 基本操作案例
1. 查看已有数据库
1 | SHOW DATABASES; |
默认会有 mysql、information_schema 等系统库。比如:
1 | +--------------------+ |
逐个解释一下:
information_schema→ 数据库结构字典mysql→ 用户与权限的核心库performance_schema→ 性能原始监控库sys→ 性能友好视图库这四个库是 系统保留库,一般不会往里面存业务数据,但在调试和管理数据库时经常会用到。
1.
information_schema
- 作用:存放数据库的 元数据(metadata),也就是“关于数据库的数据”。
- 包含的信息:
- 哪些数据库、表存在?
- 表里有哪些字段、索引?
- 权限、字符集等配置信息。
- 用途:可以通过查询它来获取数据库结构,而不是去翻文件。
2.
mysql
- 作用:存放 MySQL 核心权限控制和配置数据。
- 内容包括:
- 用户账号 (
user表)- 权限分配(哪个用户能操作哪个数据库)
- 存储过程、事件调度、时区等系统信息
- 用途:如果要新增用户,其实就是往这里写一行数据。
3.
performance_schema
- 作用:用来监控 MySQL 的运行时性能(谁在执行 SQL,消耗了多少时间、锁情况等)。
- 特点:
- 里面的表大部分是“虚拟表”,只读,用来查看性能指标。
- 不保存真实业务数据,重启后数据会刷新。
- 用途:调试慢查询、分析瓶颈。
4.
sys
- 作用:算是
performance_schema的“人性化视图”。- 特点:
- 里面封装了很多复杂 SQL,把性能信息转换成 更直观的视图。
- 比如直接告诉你“哪条 SQL 最耗时”、“哪个库最忙”。
- 用途:DBA(数据库管理员)用它来快速诊断问题。
2. 创建一个新的数据库
1 | CREATE DATABASE test; |
3. 使用/切换数据库
1 | USE test; |
4. 创建一张(数据库)表
比如建一个学生表 students:
1 | CREATE TABLE students ( |
5. (表中)插入数据
1 | INSERT INTO students (name, age, grade) VALUES |
6. 查询表数据
1 | SELECT * FROM students; |
输出结果类似:
1 | +----+--------+------+-----------------+ |
7. 更新数据
1 | UPDATE students SET grade = '大学二年级' WHERE name = '王五'; |
8. 删除数据
1 | DELETE FROM students WHERE id = 2; |
9. 补充说明
在 MySQL 里,SQL 关键字(SELECT、INSERT、UPDATE、DELETE、CREATE…)不区分大小写。所以:
1 | SELECT * FROM students; |
结果一模一样,MySQL 都能识别。不过要注意两点:
- 表名、库名是否区分大小写
- 在 Windows 下(默认不区分大小写),
students和STUDENTS是同一个表。 - 在 Linux 下(取决于
lower_case_table_names参数和文件系统),通常是区分大小写的,所以students和STUDENTS可能被当成两个不同的表。建议在 Linux(比如 CentOS)环境中 统一用小写命名数据库、表、列名,避免踩坑。
- 在 Windows 下(默认不区分大小写),
- 规范习惯
- 通常约定:SQL 关键字用大写(SELECT、WHERE、INSERT INTO),库名、表名、列名用小写(students、school、id)。
- 这样可读性更强,一眼能区分“关键字”和“自定义标识符”。
小结:
- 语法关键字:不区分大小写,大小写随你。
- 数据库名、表名、字段名:在 Linux 下可能区分大小写,建议统一小写。
- 写代码习惯:推荐“关键字大写 + 表名字段小写”。
4. 数据逻辑存储
MySQL 是关系型数据库,它的数据逻辑上就是表格结构(二维表)。
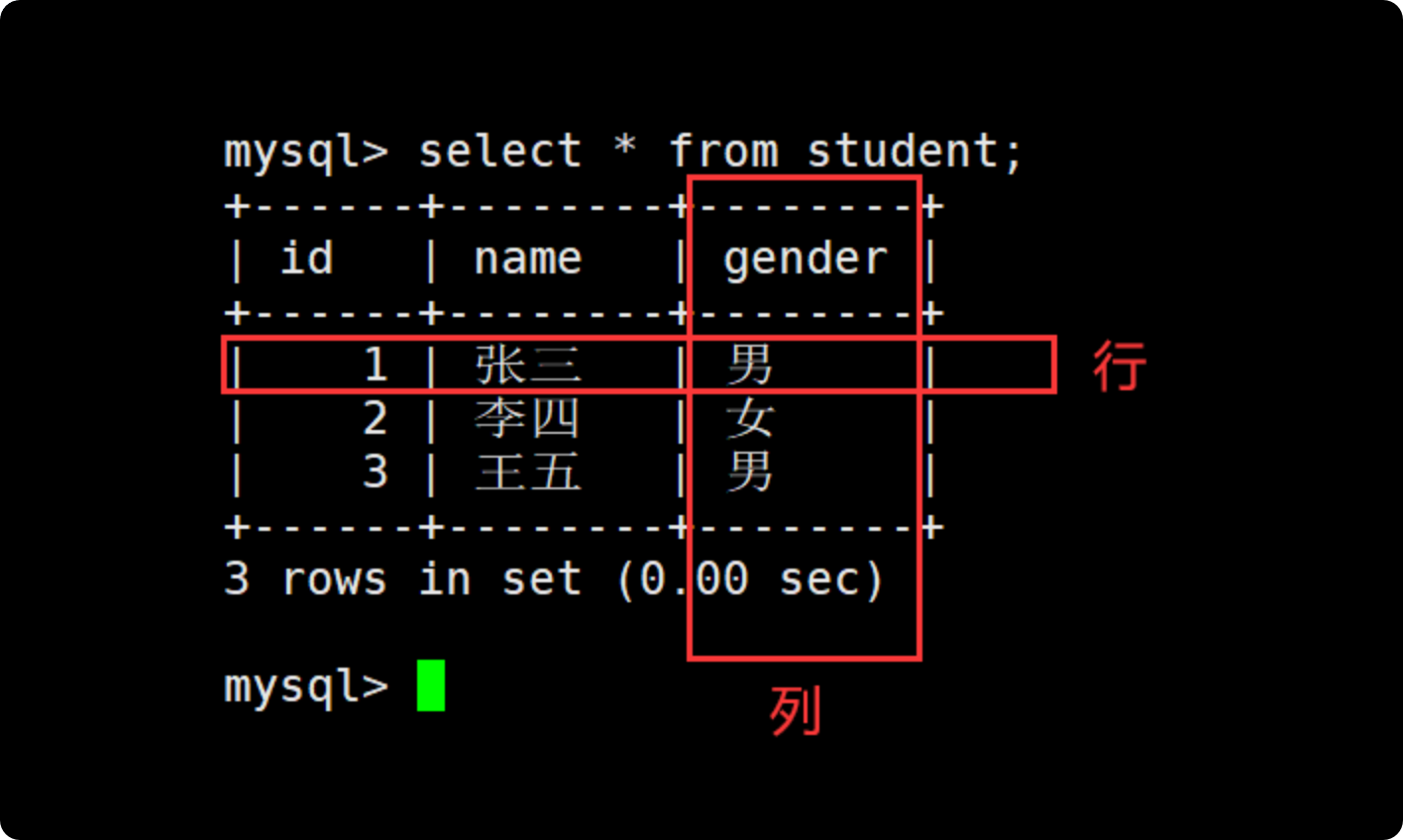
表的每一行:一条记录(比如某个用户的信息),表的每一列:一个属性(比如用户名、年龄),多个表之间通过主键、外键建立关系。物理上数据存在磁盘里,常用存储引擎是 InnoDB,它支持事务、行级锁、索引。
5. MySQL 架构
1. 基本架构一览
MySQL 是一个可移植的数据库,几乎能在当前所有的操作系统上运行,如 Unix/Linux、Windows、Mac 和 Solaris。各种系统在底层实现方面各有不同,但是 MySQL 基本上能保证在各个平台上的物理体系结构的一致性。它本质上是一个典型的 “客户端-服务器”模型 + 插件式存储引擎设计。
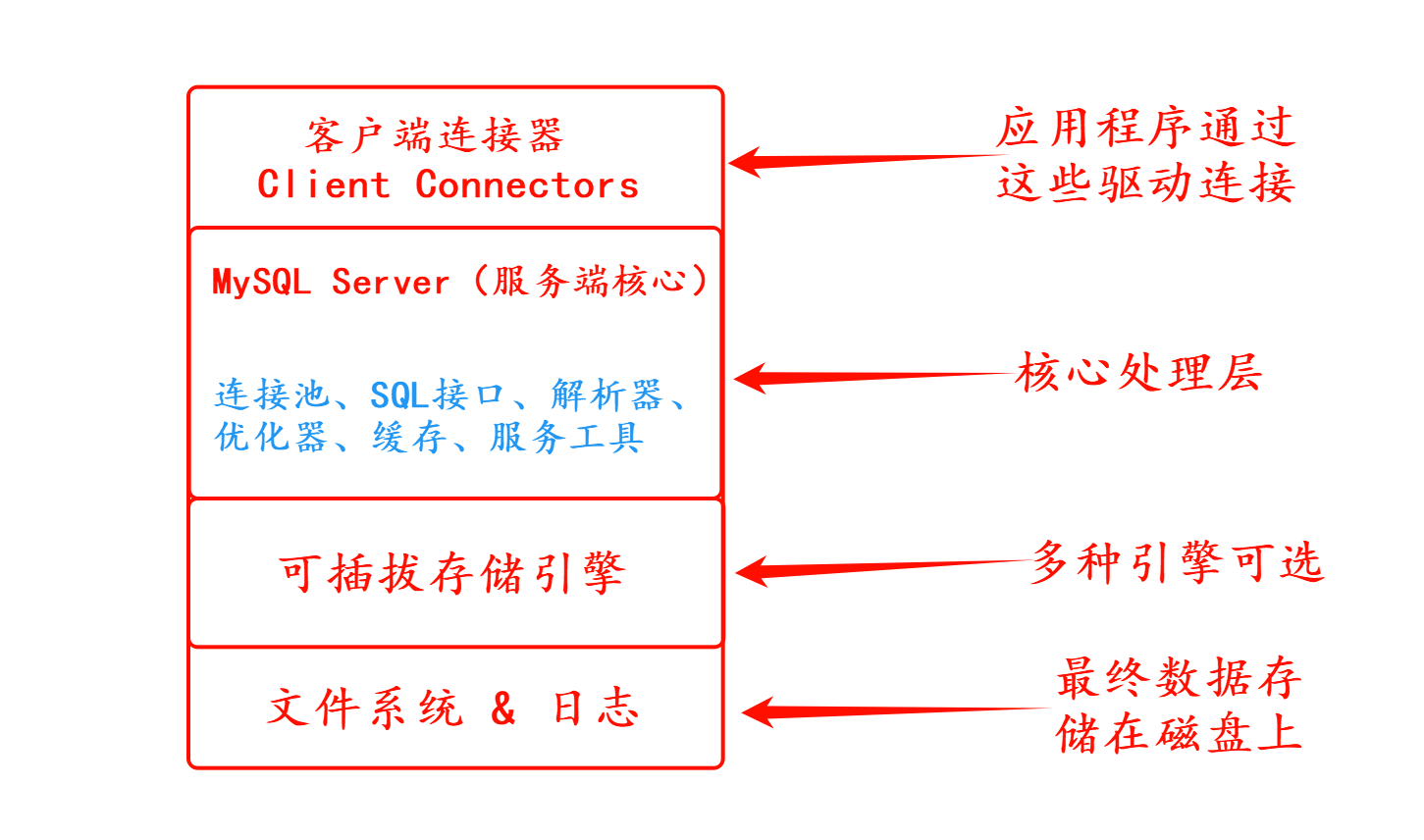
2. 详细解释
1. 最上层:客户端连接器(Client Connectors)
最上面一层,支持各种语言和接口,比如:JDBC、ODBC、.NET、PHP、Python、C API。作用:程序员写的代码通过这些接口跟 MySQL 服务器通信。
意思是:用 C++ 写程序,可以用 C++的接口连接 MySQL;用 PHP 写网站,可以用 PHP 驱动连接。
2. 中间层:MySQL Server(服务端核心)
这是 MySQL 的“大脑”,负责处理所有请求。主要包含以下模块:
| 模块 | 功能 |
|---|---|
| Connection Pool(连接池) | 管理客户端连接,进行身份验证、权限和安全。 |
| SQL Interface(SQL 接口) | 负责接收 SQL 命令(增删改查、存储过程、触发器等)。 |
| Parser(解析器) | 把 SQL 语句拆开,检查语法对不对(词法分析、语法分析)。比如 SELEC 写错就报错。 |
| Optimizer(优化器) | 选择最优执行路径、决定怎么执行 SQL 最快,比如用不用索引,先查哪个表。 |
| Caches(缓存) | 缓存查询结果和部分数据,加快重复 SQL 的速度,提升性能。 |
| Services & Utilities(服务工具) | 提供备份恢复、复制、分区、集群等高级功能。 |
这些模块共同构成了 MySQL 的“SQL 层”,处理所有 SQL 请求。
3. 下一层:(可插拔)存储引擎(Pluggable Storage Engines)
一个大特点就是 存储引擎可插拔。每张表都可以选择不同的存储引擎,都可以独立工作,就像“插件”一样插入系统中。MySQL 支持多种存储引擎,比如:
- InnoDB(默认,支持事务、行锁、外键)
- MyISAM(早期常用,不支持事务,速度快性能高)
- Memory(内存表,速度快但数据断电丢失)
- Archive(归档用,压缩存储,不适合频繁写入)
存储引擎负责真正的 数据存取、索引维护。
所谓 可插拔存储引擎,就是 MySQL 允许在同一个数据库里为不同表选择不同的存储方式(比如 InnoDB、MyISAM、Memory 等),就像电脑的 USB 插槽,可以根据需求插入不同的设备一样,从而实现灵活性和扩展性。
4. 最底层:文件系统与日志
最底层,跟操作系统交互,负责把数据落到磁盘:
- File System:如 Linux 的 ext4、Windows 的 NTFS。
- Logs and Files:各种日志文件:
binlog(二进制日志,主从复制、数据恢复用)error log(错误日志)slow log(慢查询日志)redo/undo log(事务恢复机制)- 表文件(
.ibd、.frm等)。
3. 小结
一条 SQL 语句会先由客户端发出,经过 MySQL Server 层统一做解析、优化和权限检查,再交给底层的存储引擎去执行,最后由存储引擎把数据读写到磁盘文件中。整个过程体现了 MySQL 的分层设计:SQL 层管“怎么执行”,存储引擎管“怎么存取”。
6. SQL 分类
- DDL(数据定义语言):定义数据库结构,比如建表、删表、改表结构。代表有 👉
CREATE、DROP、ALTER。 - DML(数据操作语言):操作表里的数据(增删改),比如:插入一条记录、删除用户。代表有 👉
INSERT、DELETE、UPDATE。- 其中 DQL(数据查询语言) 是 DML 的子类,用来查数据。如:
SELECT。
- 其中 DQL(数据查询语言) 是 DML 的子类,用来查数据。如:
- DCL(数据控制语言):用来管理权限和事务。代表有 👉
GRANT、REVOKE、COMMIT。
记忆口诀:DDL 定结构,DML/DQL 动数据,DCL 管权限和事务。
7. 存储引擎
1. 存储引擎是什么?
存储引擎就是 MySQL 负责数据的存储、提取、索引、更新、查询等 底层实现机制/方式的模块。
- 同样一条
CREATE TABLE,可以指定用不同引擎,决定数据如何落盘、索引方式、是否支持事务等。 - 它体现了 MySQL 的“可插拔”特性,不同引擎像插件一样,可以替换。
简单说:存储引擎决定了数据在磁盘(或内存)里“怎么存、怎么查、怎么锁、是否支持事务”等。
2. 在 CentOS 7.6 中查看存储引擎
进入 MySQL 后执行:
1 | SHOW ENGINES; -- 查看当前支持的所有存储引擎 |
一般 MySQL 8.0 默认存储引擎是 InnoDB。
3. 常见存储引擎对比表
| 特性 / 存储引擎 | InnoDB(默认,事务型) | MyISAM(读多写少) | Memory(内存表) | Archive(归档表) | NDB(集群引擎) | Federated(远程表) | CSV(文本存储) | Blackhole(黑洞) |
|---|---|---|---|---|---|---|---|---|
| 是否支持事务 | ✅ | ❌ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ |
| 锁定粒度 | 行级锁 | 表级锁 | 表级锁 | 行级锁 | 行级锁 | 依赖远程表 | 表级锁 | 表级锁 |
| 是否支持外键 | ✅ | ❌ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ |
| 是否支持 MVCC / 快照读 | ✅ | ❌ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ |
| 全文索引支持 | ✅(5.6+) | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| B-Tree 索引支持 | ✅ | ✅ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ |
| 哈希索引支持 | ❌(需手动建) | ❌ | ✅(默认) | ❌ | ✅ | ❌ | ❌ | ❌ |
| 数据存储位置 | 磁盘(.ibd 文件) | 磁盘(.MYD/.MYI) | 内存 | 磁盘(压缩格式) | 内存 + 磁盘 | 远程服务器 | 文本 CSV 文件 | 丢弃(仅 binlog) |
| 是否支持数据压缩 | ✅(表空间压缩) | ❌ | ❌ | ✅(高压缩) | ✅ | ❌ | ❌ | ❌ |
| 是否支持数据加密 | ✅(TDE / 函数) | ❌ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ |
| 存储容量限制 | 最大 64TB | 受文件系统限制 | 受内存限制 | 无明确上限 | 依赖集群规模 | 依赖远程库 | 文件大小限制 | 不存储数据 |
| 适用场景 | 高并发、事务系统 | 只读/统计/检索 | 临时表、缓存 | 历史归档、大量插入 | 高可用分布式 | 跨库访问远程表 | 数据交换 | 日志复制测试 |
| 数据持久性 | ✅ 崩溃恢复 | ✅ 但易损坏 | ❌ 重启丢失 | ✅ | ✅ | ✅(依赖远程) | ✅ | ❌(不保存) |
| 是否支持复制 | ✅ 主从复制 | ✅ 主从复制 | ❌ | ✅ | ✅(原生集群) | ❌(依赖远程库) | ❌ | ✅(常用于复制) |
| 是否支持崩溃恢复 | ✅ Undo/Redo Log | ❌ 易损坏 | ❌ | ✅ | ✅ | ❌ | ❌ | ❌ |
| 内存/资源开销 | 中等 | 低 | 高(全内存) | 低 | 高 | 低 | 低 | 极低 |
| 插入性能(批量) | 中 | 高 | 极高 | 极高 | 高 | 中等(依赖远程) | 低 | 极高(丢弃数据) |
| 查询性能 | 高(带索引) | 高(简单查询) | 极高(内存) | 低(无索引) | 高 | 取决于远程库 | 低(无索引) | ❌(无数据) |
| 默认引擎(MySQL 5.5+) | ✅ | ❌(旧版默认) | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |













