
056 高级 IO

056 高级 IO
小米里的大麦高级 IO
1. 正确认识 IO
1. IO 的本质
I/O(Input / Output)指的是 CPU 与外设之间的数据交互过程。在冯·诺依曼结构中,系统由:CPU(运算与控制)、内存(暂存数据与指令)、外设(磁盘、网卡、显示器、键盘等)组成。
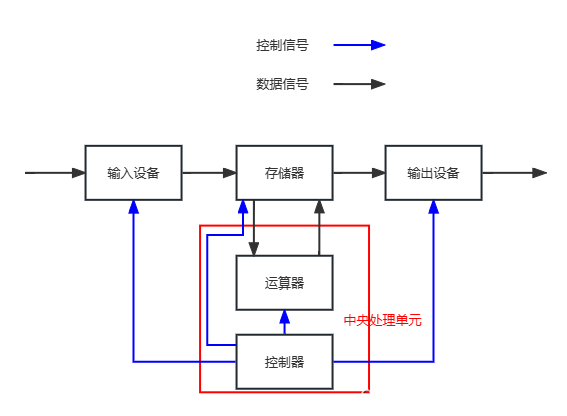
I/O 就是:数据在「内存 ↔ 外设」之间的传输。所以:
- 输入(Input):外设 → 内存(例如:键盘输入、磁盘读文件、网卡收包)。
- 输出(Output):内存 → 外设(例如:屏幕显示、磁盘写文件、网卡发包)。
2. IO 的关键特征
- 慢:外设的速度远慢于 CPU 和内存。因此,IO 通常是性能瓶颈。
- 异步性:外设工作时 CPU 可去做别的事。操作系统通过 中断、DMA(直接内存访问) 来提高效率。
3. 文件 IO 与 网络 IO
| IO 类型 | 外设 | 操作系统抽象 | 本质 |
|---|---|---|---|
| 文件 IO | 磁盘 | 文件描述符(fd) | 把数据从磁盘读入内存或写出 |
| 网络 IO | 网卡 | 套接字(socket) | 把数据从网卡缓冲区读入内存或写出 |
对操作系统来说,一切皆文件,无论是磁盘文件、管道、套接字,本质都是「文件描述符 + 缓冲区」上的读写操作。
4. 系统调用层面
C/C++ 层面对 IO 的最底层接口如下:
1 |
|
- 读文件时,数据路径是:磁盘 → 内核缓存 → 用户内存。
- 读网络时,数据路径是:网卡 → 内核缓冲区 → 用户内存。
应用层
read&&write的时候,本质就是把数据从用户层写给 OS,即“拷贝函数”。此时我们只需要知道:IO = 等 + 拷贝。要进行拷贝,必须先判断读写事件这个条件成立!什么叫做高效 IO 呢?知道 IO = 等 + 拷贝后,就可以得出结论:单位时间内,IO 的过程中,等的比重越小,IO 效率越高!反之,等的比重越大,IO 效率越低。几乎所有提高 IO 效率的策略,本质就是这个!
2. 五种 IO 模型
1. 小故事入题
张三是个钓鱼佬,他的钓鱼方式是一根儿鱼竿儿,钓鱼时就一直一动不动地盯着鱼漂,直到有鱼上钩。在这段时间内他不能干别的事,我们管这种方式叫做 阻塞式 IO。
- 对应到计算机上:
read()一调用,就会 阻塞当前线程,操作系统先等数据准备好(等待阶段),数据准备好后,再拷贝到用户空间(拷贝阶段),两步都做完,read()才返回。特点:简单、直观,但效率最低。CPU 在“等鱼”的时间被浪费掉。
- 对应到计算机上:
李四也是钓鱼佬,他也是一根儿鱼竿儿,但他的钓鱼方式是:抛完杆儿,等一会了去喝个茶回来看一看上没上鱼,看会书回来看一看,睡一觉回来看一看,跟张三说完话回来看一看(张三并不想搭理李四),这种方式叫做 非阻塞式 IO,即非阻塞轮询,特点: 线程不会被卡死,但 CPU 不停在空转查询,效率依然不高(多线程或高并发场景中非常浪费 CPU)。
王五一样,但是他很聪明,他在鱼竿上绑了一个铃铛,期间可以看书、睡觉、打游戏,摸鱼……当铃铛响了说明上鱼了,才去看鱼竿儿,这属于 信号驱动式 IO。
- 系统上:程序先注册一个信号回调函数(
sigaction),当内核检测到数据可读时,会发信号通知用户进程,用户进程再调用read()把数据拷贝到用户空间。特点:通过信号机制通知事件,比轮询更高效。但信号机制复杂、调度开销大,所以实际使用较少。
- 系统上:程序先注册一个信号回调函数(
赵六是个有钱人,他直接开了一大卡车的鱼竿儿,机械化钓鱼,就假设他布置好了 1000 根鱼竿儿,他不可能盯着每一根,于是雇了个助手,
助手负责统一盯着所有鱼竿,一旦某根竿有动静就通知他。此时水里的鱼是一定的,但赵六上鱼的概率远远高于其他人,这就是 多路复用/转接。- 这就是 select/poll/epoll 的核心思想。 系统提供一个统一的接口,一次性监听多个文件描述符(鱼竿),当其中任意一个“准备就绪”时再通知进程。特点:可同时管理大量连接(高并发)、赵六只需要等“通知”即可,效率大大提升、是高性能网络服务器(如 Nginx、Redis)最常用的模式。
田七照样是个有钱人,看到他们在钓鱼,于是也想吃鱼,就准备一起,但是很不巧临时有事要走,他一想:我就想吃鱼,怎么来的不重要,于是就叫随行的司机拿着工具去钓鱼,田七则去办其他的事情,告诉司机等他钓好鱼后直接给他打电话就行。这就是 异步 IO,值得注意的是这里的司机其实就是 OS。
- 系统中:用户调用
aio_read()之后立即返回,操作系统后台完成“数据准备 + 拷贝”两个阶段,完成后通过事件或回调通知应用。特点:真正的 非阻塞 + 无等待,CPU 可以同时干别的工作,适用于 I/O 密集型高并发场景。
- 系统中:用户调用
我们知道 IO = 等 + 拷贝,所有 IO 模型的区别,都在于这两个阶段是 谁在做、怎么做。在这个钓鱼的过程中只有田七是异步 IO,其他人都属于同步 IO,因为其他人都直接参与了等的环节,但田七则是间接做了等的操作,实际不参与 IO,田七只是发起 IO,最后拿结果就行,就像我交给你一个黑盒,我不管你干了什么,到时候我从黑盒中拿结果就行。还有一点就是同步 IO 是/属于线程同步吗?答案是老婆和老婆饼的关系 —— 没有关系!
2. 深入理解 IO = 等 + 拷贝 的思维模型
无论哪种 IO,本质都要经历两个阶段:
- 等待数据准备好(等待鱼上钩)。
- 数据从内核缓冲区拷贝到用户空间(把鱼拽上来)。
区别在于:谁来“等”(线程自己、统一管理者、还是操作系统),什么时候返回(等完再返回,还是先返回之后回调)。
| 模型类型 | 等待阶段 | 拷贝阶段 | 是否阻塞 | 谁来等 | 典型调用 | 适用场景 |
|---|---|---|---|---|---|---|
| 阻塞 I/O | 阻塞 | 阻塞 | 是 | 应用线程 | read() | 简单场景 |
| 非阻塞 I/O | 轮询 | 阻塞 | 否(轮询) | 应用线程 | fcntl(fd, O_NONBLOCK) | 少量连接 |
| 信号驱动 I/O | 信号触发 | 阻塞 | 否 | 内核发信号 | sigaction() | 特殊场合 |
| I/O 多路复用 | 阻塞等待事件 | 阻塞拷贝 | 部分阻塞 | 统一等待者(select/poll/epoll) | 高并发服务器 | 高性能 |
| 异步 I/O | 非阻塞 | 非阻塞 | 否 | 全交给内核 | aio_read() | 真正异步场景 |
3. fcntl 函数原型
1. 功能 / 作用
fcntl() —— 它是 Linux 文件描述符控制的“瑞士军刀”,非常常见于网络编程和 I/O 模型设置中,比如设置非阻塞套接字。fcntl()(file control)用于 对已打开的文件描述符进行各种控制操作。几乎所有“修改文件描述符行为”的操作都要通过它完成,例如:设置 / 清除文件描述符的标志(如非阻塞模式)、获取 / 修改文件状态、复制文件描述符、锁定文件、调整文件特性等。
2. 函数原型
1 |
|
3. 参数详解
| 参数位置 | 含义 |
|---|---|
| 第 1 个参数:fd | 要操作哪个文件描述符(文件、socket 等) |
| 第 2 个参数:cmd | 要执行的命令/控制操作(告诉内核你想干什么) |
| 第 3 个参数:arg(可选) | 如果需要,就传入新的标志值(常用“旧标志 | 新功能”) |
1. 第二个参数(cmd)—— 要执行的操作类型
| 命令(cmd) | 含义 | 第三个参数(arg) | 常用场景 |
|---|---|---|---|
| F_GETFL | 获取文件状态标志 | 无 | 读取当前 fd 的打开模式(只读、非阻塞等) |
| F_SETFL | 设置文件状态标志 | 新标志(通常是“旧标志 | 新标志”) | 修改 fd 行为,如设为非阻塞 |
| F_GETFD | 获取文件描述符标志 | 无 | 判断 fd 是否带有 FD_CLOEXEC |
| F_SETFD | 设置文件描述符标志 | FD_CLOEXEC 等 | 设置执行 exec() 时是否自动关闭 fd |
| F_DUPFD | 复制一个新的文件描述符 | 最小可用 fd 编号 | 类似 dup(),但可指定起始编号 |
| F_SETLK | 设置文件锁(非阻塞) | struct flock * | 文件加锁,不会阻塞 |
| F_SETLKW | 设置文件锁(阻塞) | struct flock * | 文件加锁,会阻塞等待 |
| F_GETLK | 获取文件锁状态 | struct flock * | 查询当前文件锁 |
实际开发中 最常用的就是 F_GETFL 和 F_SETFL,尤其用于:设置非阻塞 IO(O_NONBLOCK)、设置追加写(O_APPEND)。
2. 第三个参数(arg)—— 状态标志
| 标志 | 含义 | 常见场景 |
|---|---|---|
| O_RDONLY | 只读打开 | 打开文件用 |
| O_WRONLY | 只写打开 | 打开文件用 |
| O_RDWR | 可读可写 | 打开文件用 |
| O_APPEND | 写操作追加到文件末尾 | 日志文件 |
| O_NONBLOCK | 非阻塞模式 | 网络 I/O |
| O_SYNC | 同步写入(每次写都落盘) | 文件系统安全要求高的场景 |
| O_ASYNC | 异步 I/O 模式 | 很少单独使用 |
| O_CREAT | 不存在则创建 | 文件打开 |
| O_TRUNC | 打开时清空文件内容 | 文件重写 |
| FD_CLOEXEC | 执行 exec() 时自动关闭 fd | 防止文件描述符泄漏 |
3. 快速记忆法
| 操作类型 | 缩写记忆 | 用途 |
|---|---|---|
F_GETFL / F_SETFL | FL = File status Flags | 控制读写行为 |
F_GETFD / F_SETFD | FD = File Descriptor | 控制描述符自身属性 |
O_NONBLOCK | Non-blocking | 设置非阻塞 |
FD_CLOEXEC | Close on exec | 执行新程序时关闭 fd |
4. 返回值
- 成功: 返回值依赖于
cmd,一般为 非负数。 - 失败: 返回 -1,并设置
errno。
5. 示例:设置非阻塞套接字
1 |
|
设置成为非阻塞,如果底层 fd 数据没有就绪,recv/read/write/send, 返回值会以出错的形式返回,错误形式的两种情况:a. 真的出错,b. 底层没有就绪。怎么区分呢?需要通过 errno 区分!!!
1 |
|
4. IO 多路转接之 select 函数原型
1. 作用
select 是最早的 I/O 多路复用函数,用来 同时监控多个文件描述符(fd)是否可读、可写或有异常事件。
2. 函数原型
1 |
|
3. 参数解释
| 参数名 | 含义 |
|---|---|
nfds | 监控的最大文件描述符 + 1(例如要监控 fd=5,就写 nfds=6) |
readfds | 想监控“可读事件”的文件描述符集合(如 recv()、read() 是否不阻塞) |
writefds | 想监控“可写事件”的文件描述符集合(如 send()、write() 是否不阻塞) |
exceptfds | 监控“异常事件”的文件描述符集合(一般不用,传 NULL) |
timeout | 超时时间(阻塞多久)。传 NULL 就是 一直阻塞。 |
1. nfds 参数
nfds = 要监控的最高文件描述符编号 + 1。
- 想监控 fd 3, fd 5?最高是 5,
nfds就写5 + 1 = 6。 - 想监控 fd 1, fd 2, fd 100?最高是 100,
nfds就是100 + 1 = 101。 - 不是系统最大支持的文件描述符大小! 那个值通常很大(如 1024 或 65536),不需要监控那么多。
记住:nfds 是一个范围:select 会检查从 0 到 nfds - 1 这个范围内的所有 fd(只要在 fd_set 里设置了它们)。nfds 就是这个范围的 上限(不包含)。简化记忆:nfds = max_fd + 1。select 会在这个范围 [0, max_fd] 内,看你 fd_set 里标记了哪些 fd,然后监控它们。
2. fd_set 的本质
fd_set 是内核与用户空间之间传递“文件描述符就绪信息”的一张位图。
| 阶段 | 谁在操作 | 含义 |
|---|---|---|
| 输入阶段(用户 → 内核) | 用户调用 select() 前 | 告诉内核:“我关心这些 fd(读、写、异常)。” |
| 输出阶段(内核 → 用户) | 内核执行完 I/O 检查后 | 告诉用户:“这些 fd 已经就绪(比特位 = 1)。” |
也就是说:readfds 是输入输出双向参数(既是输入,也会被输出修改),每一位对应一个 fd,1 表示就绪;0 表示未就绪。调用后必须重新设置 fd_set,因为 select 会修改它。fd_set 的内部形式:
1 | typedef struct |
本质就是一个 位图,每个 bit 对应一个文件描述符号位(fd 号),比如:fd=3 -> fds_bits[0] 的第 3 位。select() 的核心:用户传一张“关注表”(fd_set)给内核,内核帮你看这些 fd 是否有事件,等结果出来后,内核再把“结果表”写回给你。
3. 常用辅助宏
1 | FD_CLR(int fd, fd_set* set); // 把fd从集合中移除(对应 bit = 0) |
一般是这么操作的:
1 | fd_set readfds; // 定义一个fd集合 |
调用后,readfds 会被内核修改,表示哪些 fd 已经 就绪。
4. struct timeval 的含义
timeout就是给select设置一个 最长等待时间 的 闹钟。如果在闹钟响之前有事(fd 就绪),就立即叫醒你(返回);如果闹钟响了还没事(fd 未就绪),也叫醒你(返回 0)。如果设置为永不响(NULL),就会一直睡(阻塞);如果设置为立刻响({0, 0}),就不会睡(非阻塞)。
1 | struct timeval |
{seconds, microseconds}: select 最多等待 seconds 秒 + microseconds 微秒。
- 如果在 这个时间之内,有你监控的 fd 就绪了,
select会 立即返回,告诉你哪些 fd 就绪了,剩余的等待时间会被写回到timeout结构体中(通常在实际编程中,会每次都重新设置这个值)。 - 如果 这个时间之内,没有任何你监控的 fd 就绪,
select会 超时返回(返回值为 0)。
示例:
NULL→ 永久阻塞(传统阻塞式 I/O)。{5,0}→ 最多阻塞 5 秒(带超时的阻塞)。{0,0}→ 不阻塞,非阻塞轮询式 I/O。
4. 返回值
> 0:有多少个文件描述符就绪(可读 / 可写 / 异常)。= 0:超时,没有任何事件发生,没有错误,但是也没有 fd 就绪。< 0:出错(一般是信号中断或参数错误)。
5. 使用示例
1 |
|
一个基于 select 系统调用的单进程、单线程 TCP 服务器:
完整代码请前往 GitHub 进行查看!
1 |
|
测试连接:telnet 127.0.0.1 8080,尝试输入一些内容…… 初学时,这段代码要理解其实有一定难度,让我们详细梳理一下:
初始状态:
listensock = 3,监听 socket 的 fd,0、1、2 默认被占用就不解释了。fd_array[0] = 3。fd_array[1]到fd_array[fd_num_max-1]都是-1。
第一次
Start循环:fd_set readfds被清空。- 遍历
fd_array,只有fd_array[0](值为 3) 有效,所以FD_SET(3, &readfds)。maxfds = 3。 select(4, &readfds, ...)被调用,监控 fd 3。- 假设现在 客户端 A 连接服务器。
select发现 fd 3 (监听 socket) 可读(有新连接),返回值 > 0。- 进入
Dispatcher(readfds)。 Dispatcher遍历fd_array。i=0:fd = fd_array[0] = 3。FD_ISSET(3, &readfds)为真。fd (3) == _listensock.Fd()为真。调用Accepter()。
Accepter执行:accept被调用,获取 客户端 A 的连接。- 假设此时进程内最小可用 fd 是 4(因为 0,1,2 被占用,3 是监听 socket),所以
accept返回sock = 4。 Accepter开始查找fd_array中的空闲位置:pos = 1:fd_array[1] = -1(defaultfd)。找到空闲位置,break。pos不等于fd_num_max,所以执行else分支:fd_array[1] = 4(将客户端 A 的 fd 存入数组)。PrintFd()。
第二次
Start循环:fd_set readfds被清空。- 遍历
fd_array:i=0:fd_array[0] = 3(监听 socket)。有效,FD_SET(3, &readfds)。maxfds更新为 3。i=1:fd_array[1] = 4(客户端 A 的 socket)。有效,FD_SET(4, &readfds)。maxfds更新为 4。i=2到fd_num_max-1:fd_array[i] = -1。跳过。
select(5, &readfds, ...)被调用,现在监控 fd 3 和 fd 4!- 假设现在 客户端 A 发送了一条消息 “Hello”。
select发现 fd 4 (客户端 A 的 socket) 可读(有数据到达),返回值 > 0。- 进入
Dispatcher(readfds)。 Dispatcher遍历fd_array:i=0:fd = fd_array[0] = 3。检查FD_ISSET(3, &readfds)。因为这次是 fd 4 就绪,fd 3 没就绪,所以FD_ISSET(3, &readfds)为假。跳过。i=1:fd = fd_array[1] = 4。检查FD_ISSET(4, &readfds)。因为这次是 fd 4 就绪,所以FD_ISSET(4, &readfds)为真。fd (4) != _listensock.Fd()为真。进入else分支。- 调用
Recver(4, 1)。Recver被成功调用了!
Recver执行:Recver从 fd 4 (客户端 A 的 socket) 读取数据 “Hello”,并处理它(例如打印)。
关键点:
accept返回的 不是 监听 socket 的 fd。它返回的是一个 全新的、代表新客户端连接的 socket 的 fd。这个新 fd 会被存储到fd_array中。Start循环中的for循环会 持续更新select监控的 fd 集合 (readfds)。每次循环,它都会将fd_array中所有非-1的 fd(包括监听 socket 和所有已连接的客户端 socket)都添加到监控集合中。Dispatcher循环会 持续检查fd_array中所有非-1的 fd,看它们是否在select返回的就绪集合 (readfds) 中。- 如果就绪的 fd 是 监听 socket 的 fd,说明有新连接,走
Accepter。 - 如果就绪的 fd 是
fd_array中某个已存储的客户端 socket 的 fd(即fd != _listensock.Fd()),说明这个特定客户端发送了数据,走Recver。
Accepter 中查找空闲位置的意义:
fd_array是服务器用来 追踪和管理 所有当前连接(包括监听 socket)的 本地数据结构。accept返回的 fd 必须被 记录 下来,否则服务器就无法知道有哪些客户端连接,也无法监控它们。- 查找空闲位置并存入
fd_array,是为了让Start和Dispatcher能够 知道 这个新连接的存在,并将其加入到select的监控范围和事件分发范围中。 if (pos == fd_num_max)检查是为了防止fd_array被填满,实现连接数限制。
注意: Recver 非常重要且会被使用。每当任何一个已连接的客户端发送数据时,select 就会检测到该客户端对应的 fd 就绪,Dispatcher 就会找到该 fd 在 fd_array 中的位置,并调用 Recver 来处理该客户端的数据。fd_array 和 Accepter 的查找逻辑是实现多客户端管理的关键。
6. 快速上手 select 的编写步骤(重要)
想象你是一个 服务员,要同时服务多个客户(文件描述符)。
- 准备工具:创建一个
fd_set(想象成一个 点名册),清空它 (FD_ZERO)。 - 记录客户:把你需要服务的客户(文件描述符)一个个记到点名册上 (
FD_SET)。比如客户 A (fd = 3),客户 B (fd = 5)。 - 确定范围:看看你记下的客户里,编号最大的是谁?比如是客户 B (fd = 5)。
nfds就是这个最大编号 + 1,也就是 6。告诉老板(操作系统):“我要服务编号 0 到 5 的客户”。 - 开始观察:调用
select(6, &点名册, NULL, NULL, NULL)。你开始观察点名册上记录的客户,等待他们有需要(比如按铃表示可读)。 - 响应需求:
select告诉你哪些客户按铃了。你再次查看点名册(FD_ISSET),看具体是哪个客户按的。然后去服务这个客户(比如读取数据)。 - 循环往复:回到第 1 步,继续准备、记录、观察、响应。
编写步骤:
- 初始化:创建监听 socket,绑定,监听。
- 准备容器:用一个数组(如
fd_array)或链表存储所有要监控的 fd。 - 主循环 (
Start):- 清空
fd_set。 - 遍历你的容器(
fd_array),将所有有效 fd (fd != -1) 添加到fd_set(FD_SET)。 - 同时记录这些 fd 中的 最大值 (
maxfd)。 - 调用
select(maxfd + 1, &fd_set, ...).
- 清空
- 事件分发 (
Dispatcher):- 再次遍历你的容器(
fd_array)。 - 对于每个有效 fd,用
FD_ISSET(fd, &fd_set)检查它是否在select返回的就绪集合中。 - 如果是监听 fd 就绪,调用
Accepter。 - 如果是普通连接 fd 就绪,调用
Recver或相应的处理函数。
- 再次遍历你的容器(
- 处理连接 (
Accepter):accept得到新 fd,将其添加到你的容器(fd_array)中。 - 处理数据 (
Recver):读取数据,处理。如果连接断开,从你的容器(fd_array)中移除该 fd(设置为-1)。
核心思想:用一个 容器(数组/链表)管理所有 fd,用 select 监控 这个容器里的所有 fd,用 select 的返回结果 分发 事件给相应的处理函数。
7. select 优缺点总结
优点:
- 可同时等待多个文件描述符,提高 IO 利用率。
- “等待”与“操作”分离,IO 操作本身不会被阻塞。
- 实现简单,兼容性好,几乎所有平台都支持。
缺点:
- fd 数量有限(通常上限 1024)。
- 每次调用都要重置 fd 集合,使用繁琐。
- 用户态到内核态频繁拷贝,开销大。
- 内核遍历所有 fd 检查状态,效率低。
- 用户态也需维护 fd 集合,多次遍历,复杂度高。
select 能多路等待,但机制老、开销大、扩展性差,设计比较久远,具有局限性,对初学者也并不友好,于是就有了 Poll 的多路转接方案,poll 是对 select 的改进版,解决了它的一些局限。
5. poll 的函数原型
1. 作用
poll= “用数组替代位图的 select”,功能一样但更方便、无 fd 上限。
poll 是比 select 新的 I/O 多路复用函数,用来 同时监控多个文件描述符的可读、可写或异常事件。功能和 select 一样,但使用方式更简单、限制更少。
2. 函数原型
1 |
|
3. 参数解释
| 参数名 | 含义 | 与 select 对比 |
|---|---|---|
fds | 一个 pollfd 结构体数组,每个元素描述一个要监控的 fd | 类似于 readfds / writefds / exceptfds 三个集合的合并版 |
nfds | 数组中有多少个元素,即可以传入多少个文件描述符 | 等价于 select 的 nfds(监控的 fd 数量) |
timeout | 超时/最长等待时间(毫秒) | 功能同 select 的 timeout,只是单位不同(毫秒) |
1. struct pollfd 结构体
1 | struct pollfd |
2. 事件标志(events 和 revents 的取值)
| 事件 | 描述 | 是否可作为输入 | 是否可作为输出 |
|---|---|---|---|
POLLIN | 数据(包括普通数据和优先数据)可读 | 是 | 是 |
| POLLRDNORM | 普通数据可读 | 是 | 是 |
| POLLRDBAND | 优先级带数据可读(Linux 不支持) | 是 | 是 |
| POLLPRI | 高优先级数据可读,比如 TCP 带外数据 | 是 | 是 |
POLLOUT | 数据(包括普通数据和优先数据)可写 | 是 | 是 |
| POLLWRNORM | 普通数据可写 | 是 | 是 |
| POLLWRBAND | 优先级带数据可写 | 是 | 是 |
| POLLRDHUP | TCP 连接被对方关闭,或者对方关闭了写操作,它由 GNU 引入 | 是 | 是 |
POLLERR | 错误 | 否 | 是 |
| POLLHUP | 挂起。比如管道的写端被关闭后,读端描述符上将收到 POLLHUP 事件 | 否 | 是 |
POLLNVAL | 文件描述符没有打开 | 否 | 是 |
| 常用的事件标志 | 含义 |
|---|---|
POLLIN | 可读(读缓冲区有数据) |
POLLOUT | 可写(写缓冲区可用) |
POLLERR | 错误(比如连接异常) |
POLLHUP | 对端关闭连接(挂断) |
POLLNVAL | 无效的 fd |
3. 超时/最长等待时间(timeout)含义
| 取值 | 含义 |
|---|---|
>0 | 最多等待指定毫秒数(超时返回 0) |
0 | 立即返回(非阻塞轮询) |
-1 | 一直阻塞(直到有事件) |
4. 返回值
>0: 有多少个 fd 就绪。=0: 超时。<0: 出错。
5. 使用示例
完整代码请前往 GitHub 查看。
1 |
|
6. poll 小结
1. poll 的优点
- 输入输出参数分离:
struct pollfd里有events(输入)和revents(输出),不像select那样每次都要重新设置集合。 - 监控数量不限: 不再受
fd_set的 1024 比特位限制,想监控多少个 fd,就传多少个pollfd元素,具体监控多少个由第二个参数nfds决定。 - 同时等待多个 fd,提高效率:“等”的时间可以重叠,IO 效率比阻塞式 IO 高得多。
2. poll 的缺点
- 返回后仍需遍历: 需要遍历整个
fds数组,找出哪些 fd 已经就绪。 - 用户态与内核态拷贝开销大: 每次调用都要把整个
pollfd数组复制进内核,fd 多时性能会明显下降。 - 内核仍是线性扫描: 内核依然要挨个检查每个 fd,就绪检测效率低,当 fd 数量非常大时,性能退化明显。
3. 与 select 的核心区别
| 对比项 | select | poll |
|---|---|---|
| fd 表达方式 | 位图 (fd_set) | 结构体数组 (pollfd[]) |
| fd 数量限制 | 有(通常 1024) | 理论无限(由系统资源决定) |
| 参数是否要重置 | 每次都要重新设置 | 不用重置,只更新有变化的项 |
| 内核检测机制 | 遍历所有 fd | 同样遍历,但结构更清晰 |
poll是select的改良版,解决了 fd 数量上限和参数重置的问题,但底层依然是“遍历式检测”,性能瓶颈依旧。













